Pandas crosstab()与pivot_table()和groupby()的比较
发布时间:2021-12-03
公开文章
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 设置字体为黑体,解决Matplotlib中文乱码问题
plt.rcParams['axes.unicode_minus']=False # 解决Matplotlib坐标轴负号'-'显示为方块的问题
%matplotlib inline
# 忽略警告
import warnings
warnings.filterwarnings('ignore')crosstab()与pivot_table()和groupby()的比较
#从外部导入数据
diamonds = pd.read_csv('./data/diamonds.csv')
diamonds.head()
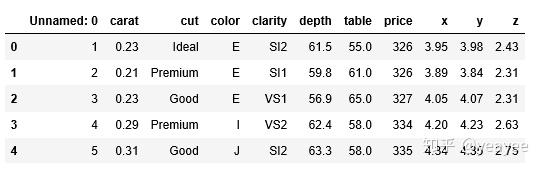
diamonds.info()
diamonds.describe()
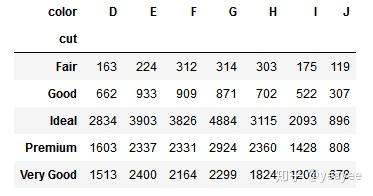
pd.crosstab(index=diamonds['cut'], columns=diamonds['color']) # 对color进行聚类count
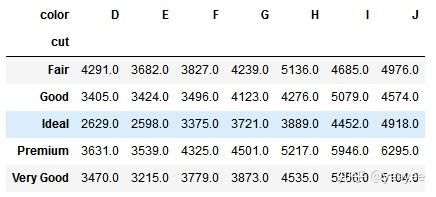
pd.crosstab(index=diamonds['cut'],
columns=diamonds['color'],
values=diamonds['price'],
aggfunc=np.mean).round(0) # 对价格进行聚类,并求price均值
使用 groupby()
diamonds.groupby(['cut', 'color'])['price'].mean().round(0)
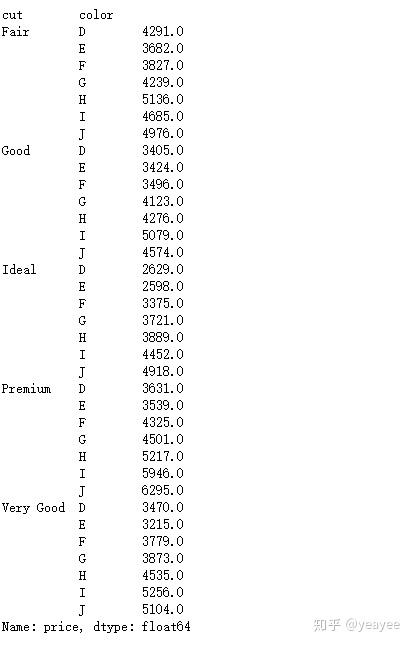
pivot_table()
diamonds.pivot_table(values='price',
index='cut',
columns='color',
aggfunc=np.mean).round(0)
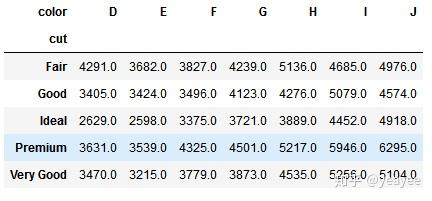
crosstab()
pd.crosstab(index=diamonds['cut'],
columns=diamonds['color'],
values=diamonds['price'],
aggfunc=np.mean).round(0)
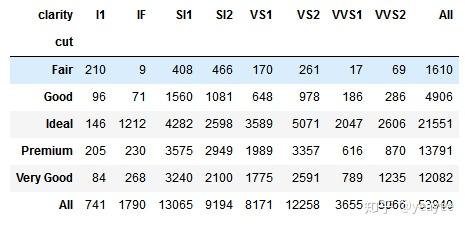
# crosstab()的另外两个有用参数是margins和margins_name(两者都存在于pivot_table()中)。设置为True时,边界计算每行和每列的和。
pd.crosstab(index=diamonds['cut'],
columns=diamonds['clarity'],
margins=True)
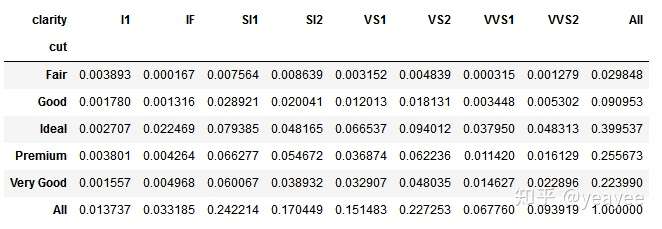
pd.crosstab(index=diamonds['cut'],
columns=diamonds['clarity'],
margins=True,
normalize=True) # normalize 标准化
pd.crosstab(index=[diamonds['cut'], diamonds['clarity']],
columns=diamonds['color']) # 复合序列
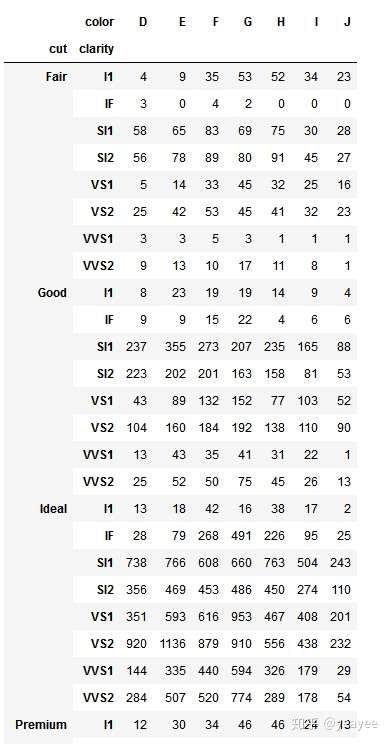
unstack() 与stack()
df1 = diamonds.groupby(['cut', 'color'])['price'].mean().round(0)
df1
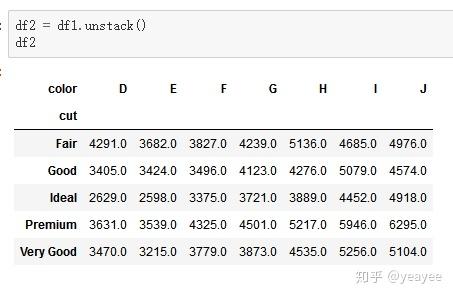
set_index和reset_index
df1
cut color
Fair D 4291.0
E 3682.0
F 3827.0
G 4239.0
H 5136.0
I 4685.0
J 4976.0
Good D 3405.0
E 3424.0
F 3496.0
G 4123.0
H 4276.0
I 5079.0
J 4574.0
Ideal D 2629.0
E 2598.0
F 3375.0
G 3721.0
H 3889.0
I 4452.0
J 4918.0
Premium D 3631.0
E 3539.0
F 4325.0
G 4501.0
H 5217.0
I 5946.0
J 6295.0
Very Good D 3470.0
E 3215.0
F 3779.0
G 3873.0
H 4535.0
I 5256.0
J 5104.0
Name: price, dtype: float64
df1.reset_index()
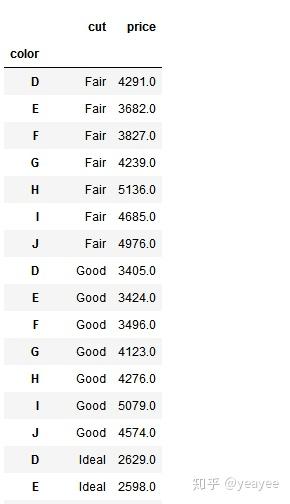
df1.reset_index().set_index('color')
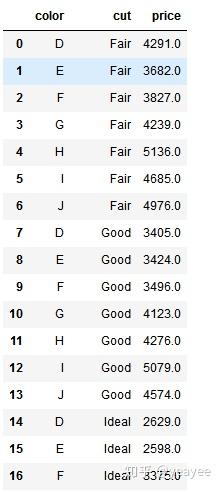
df1.reset_index().set_index('color').reset_index()
map、apply、applymap
diamonds.head()
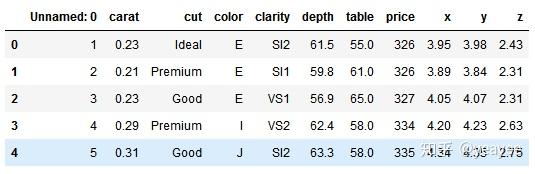
trans = dict(zip(diamonds['cut'].unique().tolist(),['理想','优质','良好','非常好','一般' ]))
diamonds['cut_trans'] = diamonds['cut'].map(trans)
diamonds.head()
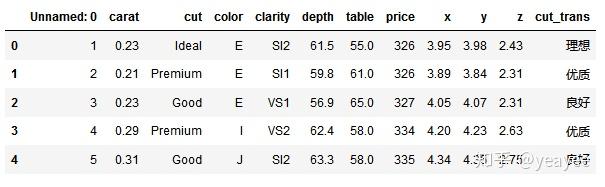
def trans2(x):
return trans[x]
diamonds['cut_trans_apply'] = diamonds['cut'].apply(trans2) # apply 函数,可以带参数,也可以指定, axis=0
diamonds.head()
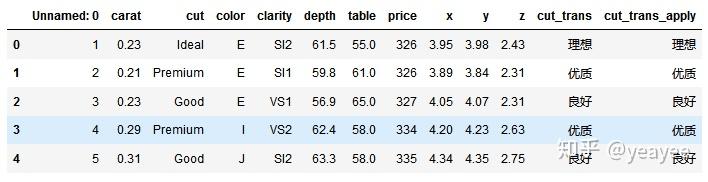
# applymap的用法比较简单,会对DataFrame中的每个单元格执行指定函数的操作
df2.applymap(lambda x:"%.1f" % x) # 含有字符串会报错,保留1位小数
df2loc和iloc
df2.loc['Fair']
color
D 4291.0
E 3682.0
F 3827.0
G 4239.0
H 5136.0
I 4685.0
J 4976.0
Name: Fair, dtype: float64
df2.iloc[0]
color
D 4291.0
E 3682.0
F 3827.0
G 4239.0
H 5136.0
I 4685.0
J 4976.0
Name: Fair, dtype: float64
df2.loc[:,['E']]
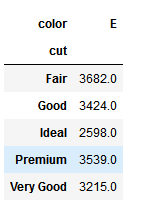
df2.iloc[:,[1]]
df2.loc[['Fair','Ideal'],['D','E']]

df2.loc[df2['D']==4291] # 取某一行,取多行匹配用到isin函数
