Python数据分析及可视化实例之全国各城市房价分析(含数据采集)
发布时间:2023-11-23
付费文章:2.0元
Talk is cheap
更多案例Python
数据采集
# !/usr/bin/env python
# coding=utf-8
import re
import os
import requests
import math
import random
import time
from bs4 import BeautifulSoup
RANDOM_DELAY = True
DELAY_MAX = 10
def get_local_time_string() :
"""
返回形如"2020-11-11"这样的时间字符串
"""
current = time.localtime()
return time.strftime("%Y-%m-%d", current)
def get_root_path() :
# 获取当前执行文件路径
root_path = os.getcwd()
return root_path
# 构造请求头,如果在复杂的防爬,如何破?
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
def create_request_headers() :
headers = dict()
headers["User-Agent"] = random.choice(USER_AGENTS)
headers["Referer"] = "http://www.ke.com"
return headers
# 贝壳找房主程序
class beike_spider() :
def __init__(self) :
pass
def format_price_info(self, name, price, total,house_adress) :
return "{0}, {1}, {2}, {3}, {4}\n".format(get_local_time_string(), name, price, total,house_adress)
def get_price_info(self, city_name) :
self.city_name = city_name
self.price_info_list = list()
target_web = 'http://{0}.fang.ke.com/loupan/'.format(city_name)
print('request target web:', target_web)
# 获得请求头部
headers = create_request_headers()
# 发起网页请求(获取总页数)
response = requests.get(target_web, timeout=10, headers=headers)
html = response.content
soup = BeautifulSoup(html, 'lxml')
# 获得response总页数
try:
page_box = soup.find_all('div', class_='page-box')[0]
matches = re.search(r'.*data-total-count="(\d+)".*', str(page_box))
total_page = int(math.ceil(int(matches.group(1)) / 10))
except Exception as e:
print("warning: only find one page for {0}".format(city_name))
print(e)
print('total pages:', total_page)
headers = create_request_headers()
# 遍历房价网页
# for i in range(1, total_page + 1) :
for i in range(1, total_page) :
target_sub_web = target_web + "pg{0}".format(i)
print('request target web:', target_sub_web)
if True == RANDOM_DELAY :
# 随机延时(0-15)秒
random_delay = random.randint(0, DELAY_MAX + 1)
print('random delay: %s S...' %(random_delay))
time.sleep(random_delay)
# 发起网页请求
response = requests.get(target_sub_web, timeout=10, headers=headers)
html = response.content
soup = BeautifulSoup(html, 'lxml')
# 获取房价相关内容
house_contents = soup.find_all("li", class_ = "resblock-list")
for house_content in house_contents :
# 获取单价
house_price = house_content.find("span", class_ = "number")
# 获取总价
house_total = house_content.find("div", class_ = "second")
# 获取小区名称
house_name = house_content.find("a", class_ = "name")
# 获取小区位置
house_adress = house_content.find("a", class_ = "resblock-location").text.strip().split('/')[0]
# 整理单价数据
try :
price = house_price.text.strip()
except Exception as e :
price = "0"
# 整理小区名称数据
name = house_name.text.replace("\n", " ")
# 整理总价数据
try :
total = house_total.text.strip().replace(u"总价", " ")
total = total.replace(u"/套起", " ")
except Exception as e :
total = "0"
# 打印单条房价信息
print("\t===> name: %s, price: %s 元/平米, total: %s,地址:%s" %(name, price, total,house_adress))
# 格式化单条房价信息,并添加到list中
price_fmt_str = self.format_price_info(name, price, total,house_adress)
self.price_info_list.append(price_fmt_str)
def store_price_info(self) :
# 创建数据存储目录
root_path = get_root_path()
store_dir_path = root_path + "/data/original_data/{0}".format(self.city_name)
is_dir_exit = os.path.exists(store_dir_path)
if not is_dir_exit :
os.makedirs(store_dir_path)
# 存储格式化的房价数据到相应日期的文件中
store_path = store_dir_path + "/{0}.csv".format(get_local_time_string())
with open(store_path, "w") as fd :
fd.write("data, name, price, total, adress\n")
for price in self.price_info_list :
fd.write(price)
# 创建贝壳网爬虫实例
spider = beike_spider()
# 获取网页房价数据
spider.get_price_info("bj") # # http://xa.fang.ke.com/,各地区的贝壳房价,自行查看拼音简写
# 存储房价数据bj
spider.store_price_info()
数据分析
import pandas as pd
from bokeh.models import ColumnDataSource, LabelSet,SingleIntervalTicker
from bokeh.layouts import gridplot
from bokeh.io import push_notebook
from bokeh.plotting import figure,output_notebook,show
from bokeh.models import ColumnDataSource, FactorRange, HoverTool
from bokeh.models.annotations import Label,LabelSet
output_notebook()
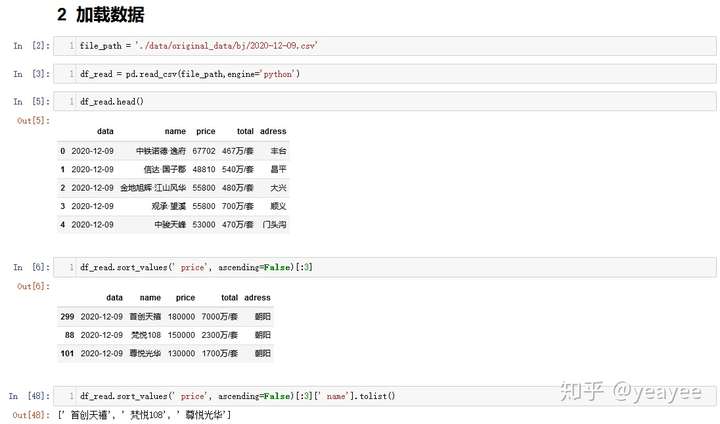
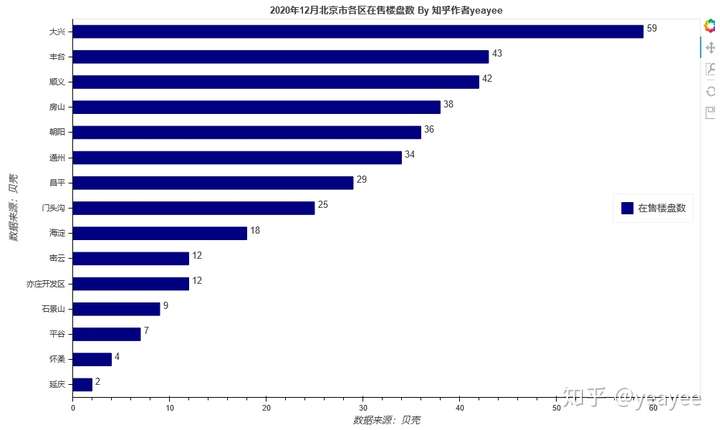
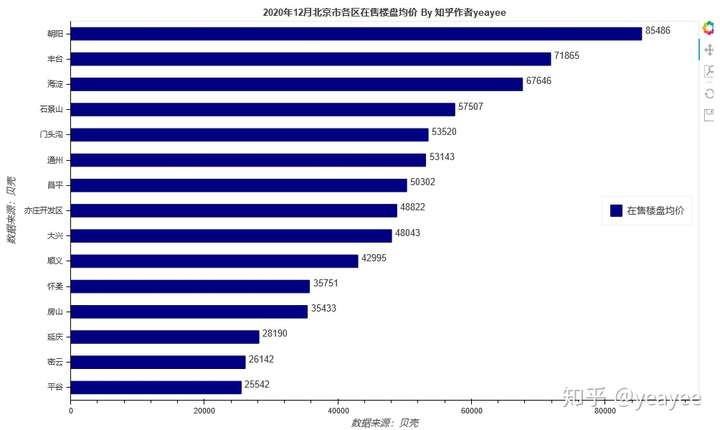
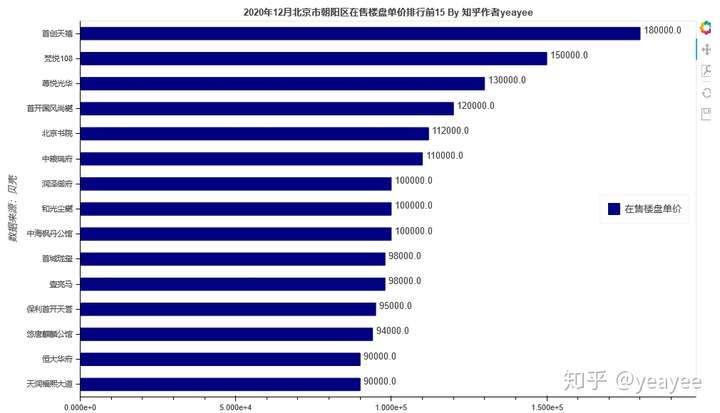
略N张图
| 点击查看更多资料:Python |
打赏2.0元
手机端:用系统浏览器访问本链接,打开支付宝完成打赏
订单号示例
1.微信中:截图保存支付宝绿码,支付宝扫码打赏,手动获取;
2.电脑端:使用手机支付宝直接扫绿码,完成打赏,自动获取;