Python数据分析及可视化实例之爬虫源码(04)
发布时间:2021-12-03
公开文章
1.背景介绍
(1)接上一弹留下的作业,使用Cookies免密码登录今日头条,并针对上一节采集的URL自动POST一条回复,经测试,今日头条的回复频率过快(3条),提交按钮就挂了。所以,本文旨在说明如何进行POST,Login登录也是一个道理。

在Code中设置Cookie时,要带上Host(如果有)。
(2)回复内容也是有技巧的,在本案例中回复内容由‘标题’,‘关键词’,及宣传广告语组成,避免被机器人认定为重复内容。
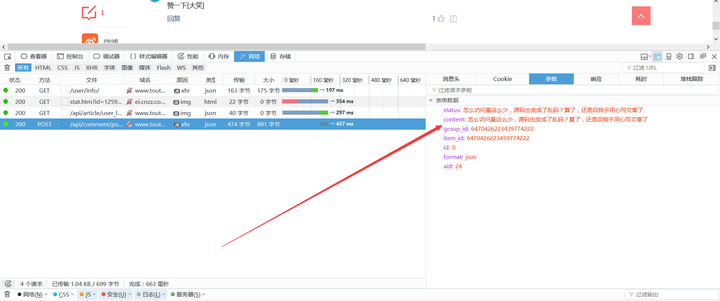
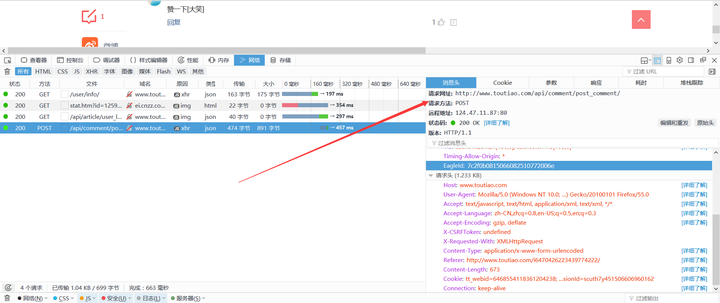
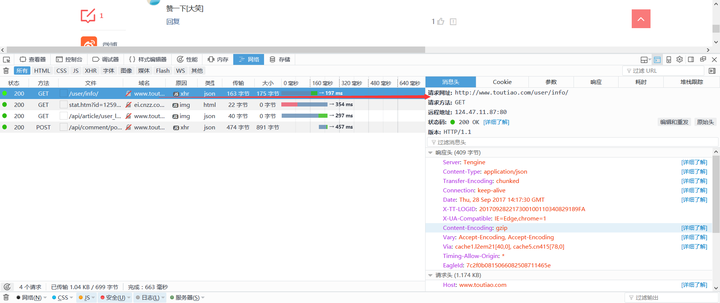
呵呵,别以为找了POST_URL然后post Data就可以搞定回复!可以明确的说,行不通。因为在提交发布按钮的时候,还在加载了几个链接,作用就是改变了Session中的Cookie。所以,在用Requests的时候,还的模拟前面的Get请求,自动更新Session。比如本案例中还需要Get请求:http://www.toutiao.com/user/info/
PS:也不知道他们的程序猿为什么要将Post数据重复成两个变量提交给数据库?
(3)没错,现在可以成功Post。扩展一下:登陆网站的POST参数相对难获取,尤其是一些JS动态生成的参数,这个时候就要用到PhantomJS。再次推荐xchaoinfo/fuck-login,该有的Fuck都有了,没有的也可以照猫画虎,我就不专门讲Post登陆,用Cookie单账号登陆采集数据就够大部分人用了。更多高级黑的操作,牵扯到灰产和恶意爬虫,不便详述(如更换IP,更换ID,更换IQ等)。
(4)下一弹是讲多线程,多进程呢?还是继续祭出神器Phantoms给度娘来一发?看客们留言哈!!!
2.源码
# coding = utf-8
import requests
import re, json
from bs4 import BeautifulSoup
import time
headers = {
'Host': 'www.toutiao.com',
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Cookie': 'tt_webid=646855411836120***8; 。。。。不要随便让人看到你的小秘密',
'Connection': 'keep-alive'
}
s = requests.session()
def post_data(base_url,post_content,post_id):
try:
# base_url = 'http://toutiao.com/group/64689424888533888/'
url2 = 'http://www.toutiao.com/user/info/'
content = s.get(url2, headers=headers) # 获取Useinfog,更新session
# soup = BeautifulSoup(content, "lxml")
# print(soup.prettify())
headers['Referer'] = base_url
url3 = 'http://www.toutiao.com/api/comment/post_comment/'
data = {
'status':post_content,
'content': post_content,
'group_id':post_id,
'item_id':post_id
}
s.post(url3, headers=headers, data=data) # 评论文章
print('评论成功啦,嚯嚯')
except:
print('掉坑里了,爬起来')
pass
f_lines = open('sorted.txt','r',encoding='utf-8').readlines()
posted_urls = open('posted.txt','r',encoding='utf-8').read()
# print(f_lines[0].strip().split(',')) # 实现记录已评论的Url,中断后可以接着评论
for f_line in f_lines:
if 'http://toutiao.com/group/' in f_line: # 说明是可以评论的文章
line_list = f_line.strip().split(',')
base_url = line_list[1]
print(base_url)
post_content = '大神,你发的《'+ line_list[2]+'》很有借鉴意义,能否转发呢?'
# print(post_content)
post_id = base_url.split('/')[-2]
if base_url not in posted_urls : # 进入下一个循环
try:
time.sleep(3)
post_data(base_url,post_content,post_id)
f_posted = open('posted.txt','a',encoding='utf-8')
f_posted.write(base_url+'\n')
f_posted.close()
except:
print('又他妈掉坑里了,爬起来')
pass
else:
print('曾经评论过了')