Python数据分析及可视化实例之爬虫源码(03)
发布时间:2021-12-03
公开文章
1.背景介绍
(1)话说今日头条在我乎挖走了‘三百勇士’,于是就想知道这些勇士中有木有练Py大法的,是不是真的勇士。本着我不入地狱,谁入地狱的精神,注册并体验了一下,我曹,这不就是微信公众号、快手、秒拍、斗鱼、陌陌、淘宝客网站的杂交嘛。
(2)搜索了一下,响应原来是Json,嚯嚯,Ajax我喜欢,只要找到路径直接Json.loads(),连BeautifulSoup都省了,更不用说Re神器了,快走起!
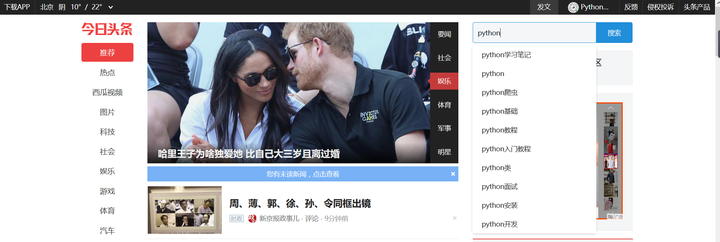
别说,关键词联想还不错,那么就多体验几个有关于Py大法的关键词,初步看看。
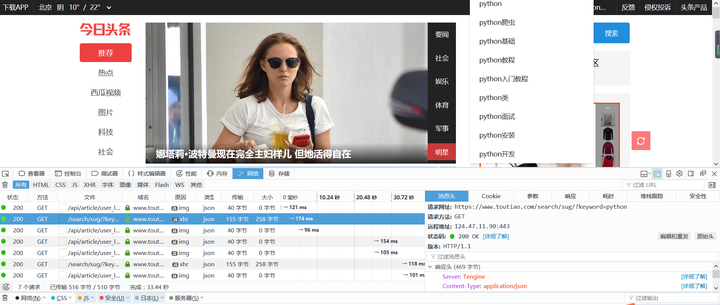
再拉近一点距离,竟然是瀑布流,下拉自动加载页面,经核实一个关键词就多下拉8页,每页20条数据;仔细算算,也就是1个关键词只能获取160条消息,那么意味着要采集更多的数据,只能发现更多的关键词。于是我采集一组关键词:
'''Python学习笔记
Python教程
Python开发
Python函数
Python
Python3
Python爬虫
Python基础
Python网络爬虫
Python基础教程
Python编程
Python实战
Python学习
Python公开课
python手机
python window
python类
python入门教程
python面试'''
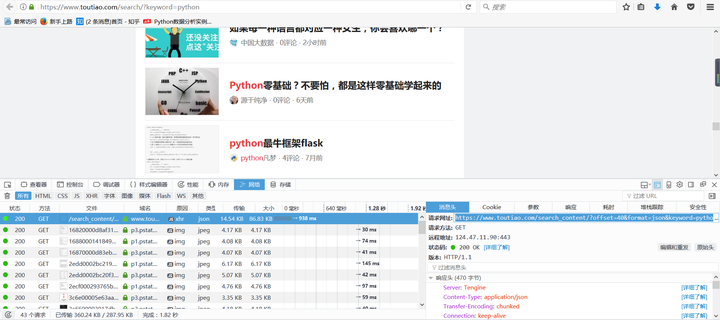
(3)Ajax妖怪,哪里逃:逐条查看响应内容!
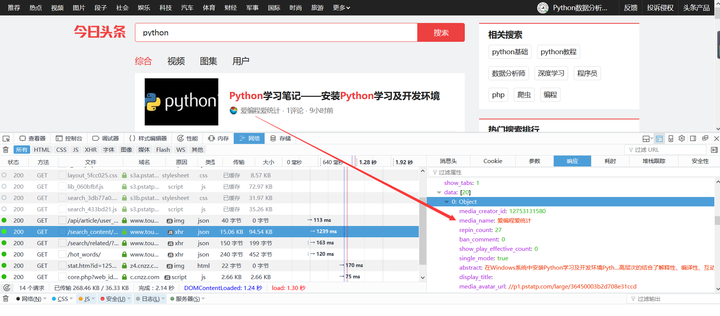
(4)有路径,有Json,Perfect。共采集文章1727篇,从评论数量看看头牌都有哪些?
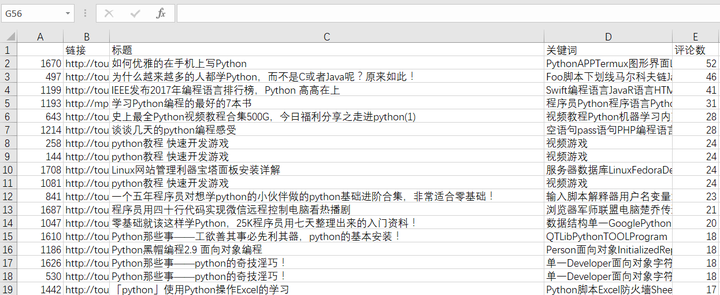
手动看看评论,你们绝对猜不到,标题党占9成,符合头条的风格。
(5)有NLP基础的可以对评论进行情感分析(有NLP基础的还TMD看这篇破文章!)
好吧,POST自动评论,且听下回分析。。。
2.源码
# coding:utf-8
import requests
import json, time
# 本节采用请求头直接采集
# url = 'https://www.toutiao.com/search_content/?offset=0&format=json&keyword=python&autoload=true&count=20&cur_tab=1'
# https://www.toutiao.com/search_content/?offset=20&format=json&keyword=python&autoload=true&count=20&cur_tab=1
# page = 8*20 最大到offset160
pkeywords = '''Python学习笔记
Python教程
Python开发
Python函数
Python
Python3
Python爬虫
Python基础
Python网络爬虫
Python基础教程
Python编程
Python实战
Python学习
Python公开课
python手机
python window
python类
python入门教程
python面试'''.split('\n')
# print(pkeywords)
def get_data(url):
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']
for n in news:
if 'title' in n:
title = n['title']
comments_count = n['comments_count']
url = n['article_url']
keyword = ''.join(n['keywords'].split(','))
# print(url,'|',title,'|',keyword,'|',comments_count)
line = url + '|' + title + '|' + keyword + '|' + str(comments_count) + '\n'
print(line)
f = open('keyds.txt', 'a', encoding='utf-8') # TXT文本保存
f.write(line)
f.close()
if __name__ == '__main__':
for kw in pkeywords:
for i in range(9):
url = 'https://www.toutiao.com/search_content/?offset=' + str(
i * 20) + '&format=json&keyword=' + kw + '&autoload=true&count=20&cur_tab=1'
print(i, kw, url)
try:
get_data(url)
except:
print('爬虫掉坑里了,爬起来继续')
pass