Python数据分析及可视化实例之房屋制热、制冷功率预测
发布时间:2021-12-04
付费文章:2.0元
付费后可以查看加密内容,获取下载链接,若链接失效,联系微信yeeyea
加载数据
import os
import pandas as pd
df = pd.read_csv("CYKEZR.csv",encoding='gb18030' )
df.head()relative compactness surface area wall area roof area overall height orientation glazing area glazing area distribution heating load cooling load 0 0.98 514.5 294.0 110.25 7.0 2 0.0 0 15.55 21.33 1 0.98 514.5 294.0 110.25 7.0 3 0.0 0 15.55 21.33 2 0.98 514.5 294.0 110.25 7.0 4 0.0 0 15.55 21.33 3 0.98 514.5 294.0 110.25 7.0 5 0.0 0 15.55 21.33 4 0.90 563.5 318.5 122.50 7.0 2 0.0 0 20.84 28.28
是否有空值
df.isnull().any()
relative compactness False
surface area False
wall area False
roof area False
overall height False
orientation False
glazing area False
glazing area distribution False
heating load False
cooling load False
dtype: bool数据分割
X = df.iloc[:,:-2]
y_heating = df['heating load']
y_cooling = df['cooling load']
# 解决中文显示问题
# from yellowbrick.style.rcmod import set_aesthetic
# set_aesthetic(font = 'SimHei')
import matplotlib
matplotlib.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False # 用来正常显示负号回归分析
制热
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso
from yellowbrick.regressor import PredictionError
X_train, X_test, y_train, y_test = train_test_split(X, y_heating, test_size=0.2, random_state=42)
# 可视化及验证
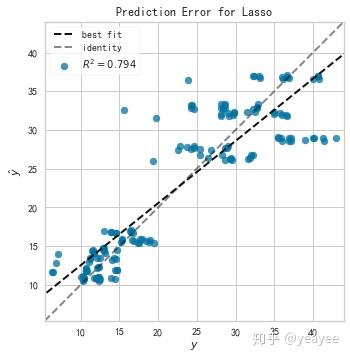
model = Lasso()
visualizer = PredictionError(model) # line_color='r'
visualizer.fit(X_train, y_train)
print(visualizer.score(X_test, y_test))
visualizer.poof()
0.7940649566807682
制冷
X_train, X_test, y_train, y_test = train_test_split(X, y_cooling, test_size=0.2, random_state=42)
# 可视化及验证
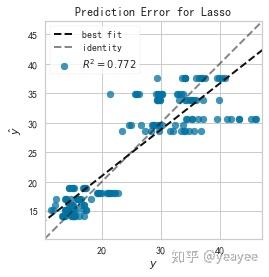
model = Lasso()
visualizer = PredictionError(model) # line_color='r'
visualizer.fit(X_train, y_train)
print(visualizer.score(X_test, y_test))
visualizer.poof()
0.7722075069396912
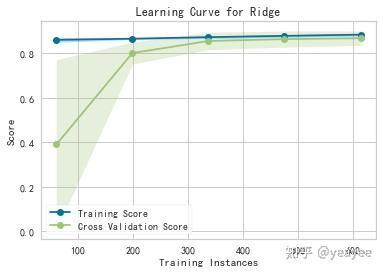
学习曲线
制热
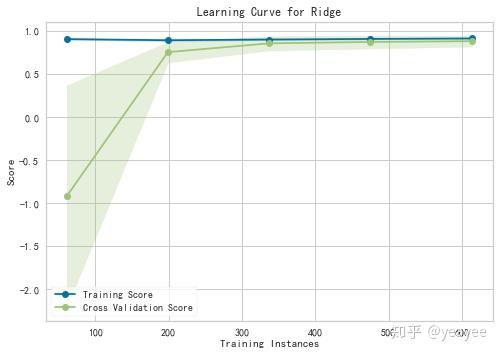
from yellowbrick.model_selection import LearningCurve
model = Ridge()
visualizer = LearningCurve(model, cv=5)
visualizer.fit(X, y_heating)
visualizer.poof()
制冷
model = Ridge()
visualizer = LearningCurve(model, cv=5)
visualizer.fit(X, y_cooling)
visualizer.poof()
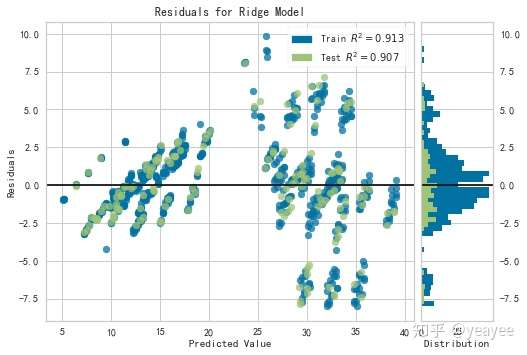
残差图
制热
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from yellowbrick.regressor import ResidualsPlot
# 创建训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_heating, test_size=0.2, random_state=42)
# 可视化及验证
model = Ridge()
visualizer = ResidualsPlot(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
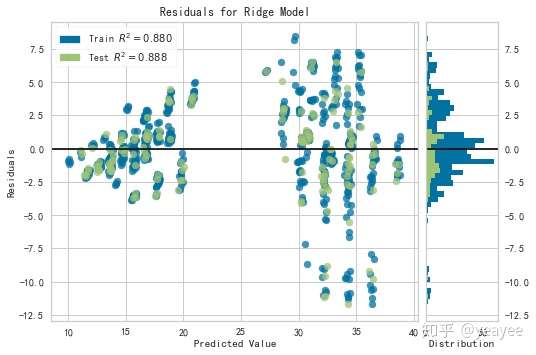
制冷
# 创建训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_cooling, test_size=0.2, random_state=42)
# 可视化及验证
model = Ridge()
visualizer = ResidualsPlot(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
打赏2.0元
手机端:用系统浏览器访问本链接,打开支付宝完成打赏
订单号示例
1.微信中:截图保存支付宝绿码,支付宝扫码打赏,手动获取;
2.电脑端:使用手机支付宝直接扫绿码,完成打赏,自动获取;