Python数据分析及可视化实例之商品销量预测
发布时间:2023-04-06
付费文章:2.0元
Talk is cheap
更多案例Python
加载数据
import pandas as pd
df=pd.read_excel('MTPOAE.xls',index_col='序号')
df.head()天气 是否周末 是否有促销 销量 序号 1 坏 是 是 高 2 坏 是 是 高 3 坏 是 是 高 4 坏 否 是 高 5 坏 是 是 高
df.isnull().any()
天气 False
是否周末 False
是否有促销 False
销量 False
dtype: bool
df['销量'].unique()
array(['高', '低'], dtype=object)
df['天气'].unique()
array(['坏', '好'], dtype=object)训练集、目标集分割
X0, y0 = df.iloc[:,:-1],df.iloc[:,-1]
from sklearn.preprocessing import OrdinalEncoder, LabelEncoder
X = OrdinalEncoder().fit_transform(X0)
y = LabelEncoder().fit_transform(y0)
X,y
(array([[0., 1., 1.],
[0., 1., 1.],
[0., 1., 1.],
[0., 0., 1.],
[0., 1., 1.],
[0., 0., 1.],
[0., 1., 0.],
[1., 1., 1.],
[1., 1., 0.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[0., 1., 1.],
[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.],
[1., 0., 0.],
[0., 0., 0.],
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 0.],
[0., 1., 0.],
[1., 0., 1.],
[1., 0., 1.],
[0., 0., 0.],
[0., 0., 0.],
[1., 0., 0.],
[0., 1., 0.],
[1., 0., 1.],
[1., 0., 0.],
[1., 0., 0.]]),
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]))
# 解决中文显示问题
from yellowbrick.style.rcmod import set_aesthetic
set_aesthetic(font = 'SimHei')
classes = df.columns.tolist()[:-1]
classes # 0,1,2
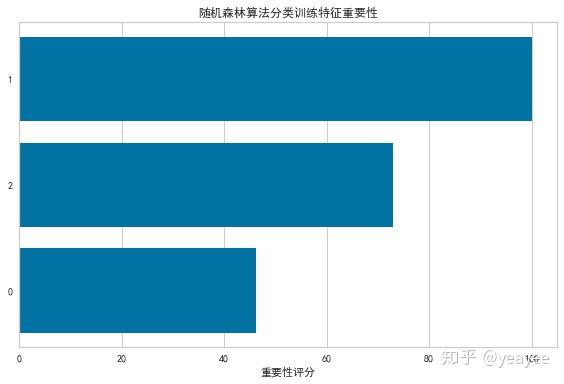
['天气', '是否周末', '是否有促销']特征重要性
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.features.importances import FeatureImportances
model = RandomForestClassifier(n_estimators=10)
viz = FeatureImportances(model,title="随机森林算法分类训练特征重要性",xlabel='重要性评分')
viz.fit(X, y)
viz.poof()
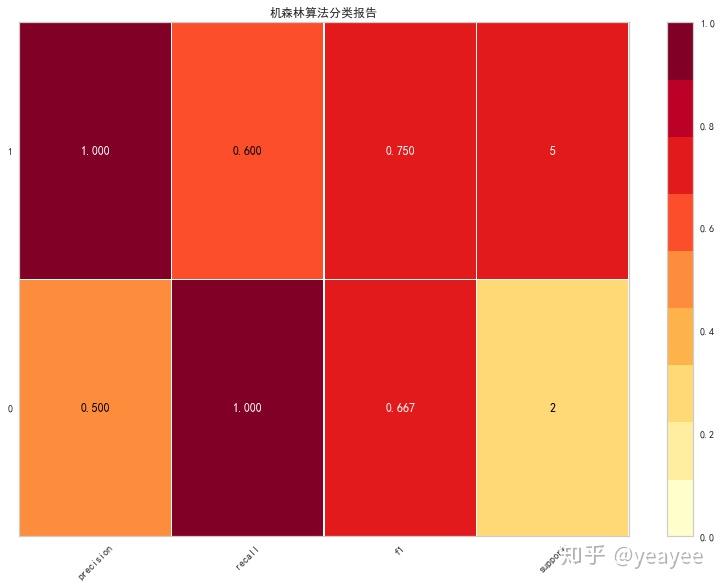
分类报告
from sklearn.model_selection import train_test_split as tts
X_train, X_test, y_train, y_test = tts(X, y, test_size =0.2, random_state=10)
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import ClassificationReport
model = RandomForestClassifier(n_estimators=10)
visualizer = ClassificationReport(model, support=True,size=(800, 600),title="机森林算法分类报告")
visualizer.fit(X_train, y_train)
print('得分:',visualizer.score(X_test, y_test))
visualizer.poof()
得分: 0.7142857142857143
预测销量
X_test
array([[0., 0., 1.],
[0., 0., 0.],
[0., 1., 1.],
[1., 1., 1.],
[0., 0., 1.],
[0., 0., 1.],
[1., 1., 1.]])
model.predict(X_test) # 输出每组数据的预测结果的标签值,0销量低,1销量高
array([0, 0, 1, 1, 0, 0, 1])
付费后可以查看加密内容,获取下载链接,若链接失效,联系微信yeeyea
注1:支付宝扫下图绿码打赏后,再点击 直接获取↑
注2:如忘记保存或后续查看,可凭订单号 手动获取