广东各地区房价多维度分析
发布时间:2023-06-04
付费文章:2.0元
内含代码及各区房价数据集
代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option('display.max_columns', 10)
pd.set_option('display.max_rows', 10)
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #当坐标轴有负号的时候可以显示负号
import os,re
# 越秀区、荔湾区、海珠区、天河区、白云区、黄埔区、番禺区、花都区、南沙区、增城区、从化区
files =['data/'+i for i in os.listdir('data/')]
files
['data/baiyun.csv',
'data/conghua.csv',
'data/haizhu.csv',
'data/huadou.csv',
'data/huangpu.csv',
'data/liwan.csv',
'data/nansha.csv',
'data/panyu.csv',
'data/tianhe.csv',
'data/yuexiu.csv',
'data/zengcheng.csv']合并区域
利用python进行数据分析按照房源建造时间划分的房价对比;处理按面积划分的房价对比(对比每单位面积房价);买房者关注因素分析(关注度);地铁距离与房价情况分析(是否近地铁)
a = '越秀区、荔湾区、海珠区、天河区、白云区、黄埔区、番禺区、花都区、南沙区、增城区、从化区'.split('、')
b = 'data/yuexiu.csv、data/liwan.csv、data/haizhu.csv、data/tianhe.csv、data/baiyun.csv、data/huangpu.csv、data/panyu.csv、data/huadou.csv、data/nansha.csv、data/zengcheng.csv、data/conghua.csv'.split('、')
area = dict(zip(b,a))
dfs = []
for i in files:
dfi = pd.read_csv(i)
dfi['区域'] = area[i]
dfs.append(dfi)
df = pd.concat(dfs,axis=0) # 合并各区房源信息
df.head()| 简述 | 地点 | 房源情况 | 关注度 | 是否近地铁 | 房价 | 每平方米房价 | 区域 |
|---|
df.tail()| 简述 | 地点 | 房源情况 | 关注度 | 是否近地铁 | 房价 | 每平方米房价 | 区域 |
|---|
df.shape # 构造整体的Dataframe
(9900, 8)数据清洗
def get_pall(x): # 房价
price =x.strip().strip('万')
return float(price)
df['房价2'] = df['房价'].apply(get_pall)
def get_price(x): # 价格
price = re.findall('\d+\.?\d*',x)[0]
return float(price)
df['单价'] = df['每平方米房价'].apply(get_price)
def get_time(x): # 时间
for i in x.split('|'):
if '年建' in i:
t = i.strip().strip('年建')
return t
df['时间'] = df['房源情况'].apply(get_time)
def get_area(x): # 面积
for i in x.split('|'):
if '平米' in i:
area = i.strip().strip('平米')
return float(area)
df['面积'] = df['房源情况'].apply(get_area)
def attention(x): # 关注
for i in x.split('/'):
if '关注' in i:
att = i.strip().strip('人关注')
return int(att)
df['关注人数'] = df['关注度'].apply(attention)
def tunnel(x): # 地铁
try:
if '地铁' in x:
return 1
else:
return 0
except:
return 0
df['地铁'] = df['是否近地铁'].apply(tunnel)
df.head()| 简述 | 地点 | 房源情况 | 关注度 | 是否近地铁 | ... | 单价 | 时间 | 面积 | 关注人数 | 地铁 |
|---|
5 rows × 14 columns
df.columns
Index(['简述', '地点', '房源情况', '关注度', '是否近地铁', '房价', '每平方米房价', '区域', '房价2', '单价',
'时间', '面积', '关注人数', '地铁'],
dtype='object')
df=df.dropna() # 删除缺失值
df = df[['区域', '房价2', '单价','时间', '面积', '关注人数', '地铁']]
df.head()| 区域 | 房价2 | 单价 | 时间 | 面积 | 关注人数 | 地铁 |
|---|
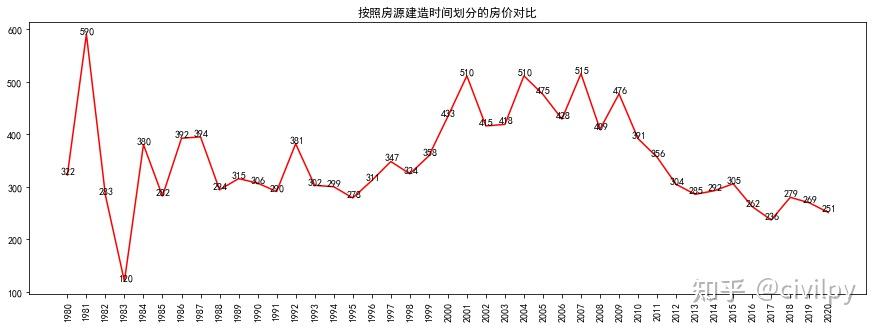
# df = df[df['区域']=='天河区'] # 如果要分析某一个区,将本行注释取消按照房源建造时间划分的房价对比
df_price = df.groupby('时间')['房价2'].mean().round(2)
plt.figure(figsize=(15, 5))
data = df_price.values
labels = df_price.index
plt.plot(range(len(data)), data,color='r')
plt.xticks(range(len(data)),labels)
for x,y in zip(range(len(data)), data):
plt.text(x+0.05,y+0.05,'%i' %y, ha='center',va='bottom')
plt.xticks(rotation=90)
plt.title("按照房源建造时间划分的房价对比")
plt.show()
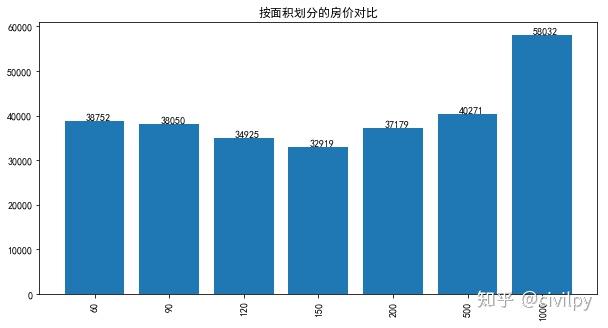
按面积划分的房价对比(对比每单位面积房价)
area_groups=pd.cut(df['面积'],bins=[0,60,90,120,150,200,500,1000], labels=["60","90","120","150","200","500","1000"])
df['面积2'] = area_groups
df_price = df.groupby('面积2')['单价'].mean()
plt.figure(figsize=(10, 5))
data = df_price.values
labels = df_price.index
plt.bar(range(len(data)), data,tick_label=labels)
for x,y in zip(range(len(data)), data):
plt.text(x+0.05,y+0.5,'%i' %y, ha='center',va='bottom')
plt.xticks(rotation=90)
plt.title("按面积划分的房价对比")
plt.show()
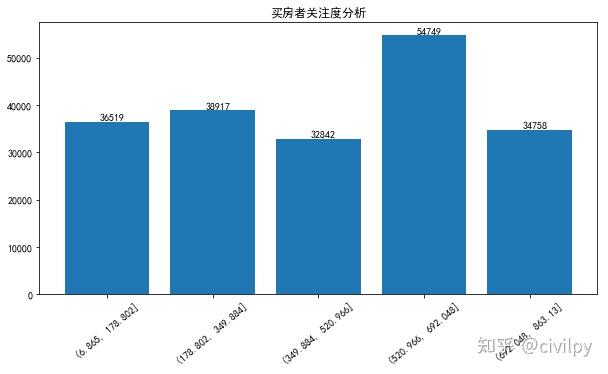
买房者关注因素分析(关注度)
att_groups=pd.cut(df['面积'],bins=5)
df['att_groups']=att_groups
df_price = df.groupby('att_groups')['单价'].mean()
plt.figure(figsize=(10, 5))
data = df_price.values
labels = df_price.index
plt.bar(range(len(data)), data,tick_label=labels)
for x,y in zip(range(len(data)), data):
plt.text(x+0.05,y+0.5,'%i' %y, ha='center',va='bottom')
plt.xticks(rotation=40)
plt.title("买房者关注度分析")
plt.show()
地铁距离与房价情况分析(是否近地铁)
df_tunnel = df.groupby('地铁')['区域'].count()
plt.figure(figsize=(5, 5))
labels = ['无地铁','有地铁']
sizes = df_tunnel.values.tolist()
plt.pie(sizes,labels=labels,autopct='%1.1f%%',shadow=False,startangle=150)
plt.title("地铁距离与房价情况分析")
plt.show()
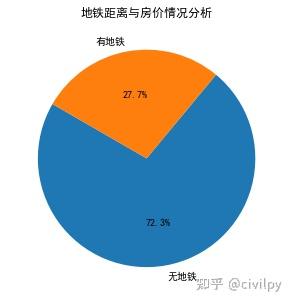
df_tunnel_price = df.groupby('地铁')['单价'].mean()
df_tunnel_price # 有地铁价格比无地铁高4000左右
地铁
0 35538.495992
1 39535.855573
Name: 单价, dtype: float64
注1:支付宝扫下图绿码打赏后,再点击 直接获取↑
注2:如忘记保存或后续查看,可凭订单号 手动获取