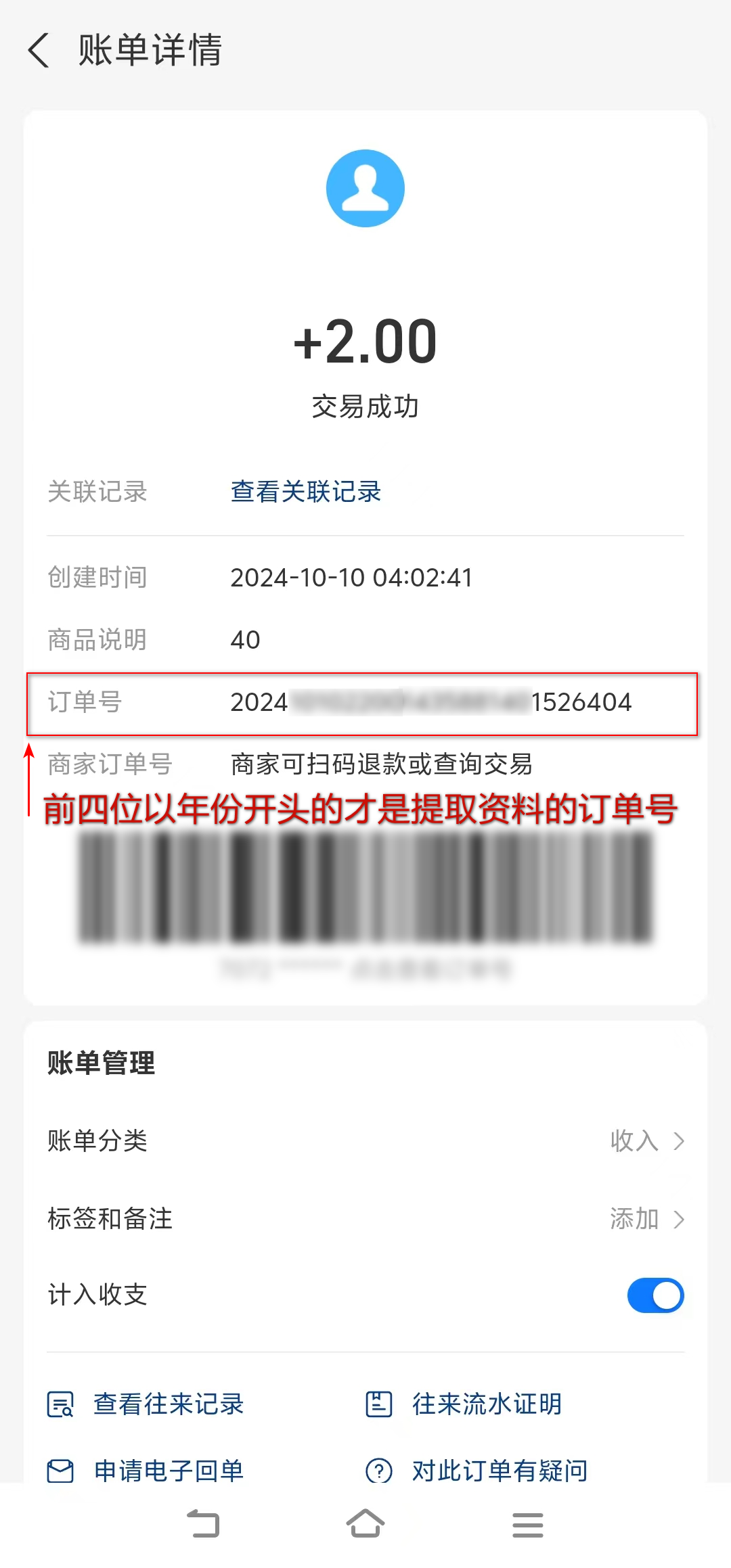
Aprior与FPTree(fp_growth)算法比较
发布时间:2023-04-03
付费文章:6.6元
Aprior
#-*- coding: utf-8 -*-
# 参考 https://blog.csdn.net/weixin_39220714/article/details/83595519
import os
import time
import csv
from tqdm import tqdm
def load_data(path):#根据路径加载数据集
ans=[]#将数据保存到该数组
with open(path,"r") as f:
reader=csv.reader(f)
for row in reader:
data = row[1].strip('{').strip('}').split(',')
row=list(set(data))#去重,排序
row.sort()
ans.append(row)#将添加好的数据添加到数组
return ans#返回处理好的数据集,为二维数组
def save_rule(rule,path):#保存结果到txt文件
with open(path,"w") as f:
f.write("index confidence"+" rules\n")
index=1
for item in rule:
s=" {:<4d} {:.3f} {}=>{}\n".format(index,item[2],str(list(item[0])),str(list(item[1])))
index+=1
f.write(s)
f.close()
print("result saved,path is:{}".format(path))
class Apriori():
def create_c1(self,dataset):#遍历整个数据集生成c1候选集
c1=set()
for i in dataset:
for j in i:
item = frozenset([j])
c1.add(item)
return c1
def create_ck(self,Lk_1,size):#通过频繁项集Lk-1创建ck候选项集
Ck = set()
l = len(Lk_1)
lk_list = list(Lk_1)
for i in range(l):
for j in range(i+1, l):#两次遍历Lk-1,找出前n-1个元素相同的项
l1 = list(lk_list[i])
l2 = list(lk_list[j])
l1.sort()
l2.sort()
if l1[0:size-2] == l2[0:size-2]:#只有最后一项不同时,生成下一候选项
Ck_item = lk_list[i] | lk_list[j]
if self.has_infrequent_subset(Ck_item, Lk_1):#检查该候选项的子集是否都在Lk-1中
Ck.add(Ck_item)
return Ck
def has_infrequent_subset(self,Ck_item, Lk_1):#检查候选项Ck_item的子集是否都在Lk-1中
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck not in Lk_1:
return False
return True
def generate_lk_by_ck(self,data_set,ck,min_support,support_data):#通过候选项ck生成lk,并将各频繁项的支持度保存到support_data字典中
item_count={}#用于标记各候选项在数据集出现的次数
Lk = set()
for t in tqdm(data_set):#遍历数据集
for item in ck:#检查候选集ck中的每一项是否出现在事务t中
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:#将满足支持度的候选项添加到频繁项集中
if item_count[item] >= min_support:
Lk.add(item)
support_data[item] = item_count[item]
return Lk
def generate_L(self,data_set, min_support):#用于生成所有频繁项集的主函数,k为最大频繁项的大小
support_data = {} #用于保存各频繁项的支持度
C1 = self.create_c1(data_set) #生成C1
L1 = self.generate_lk_by_ck(data_set, C1, min_support, support_data)#根据C1生成L1
Lksub1 = L1.copy() #初始时Lk-1=L1
L = []
L.append(Lksub1)
i=2
while(True):
Ci = self.create_ck(Lksub1, i) #根据Lk-1生成Ck
Li = self.generate_lk_by_ck(data_set, Ci, min_support, support_data) #根据Ck生成Lk
if len(Li)==0:break
Lksub1 = Li.copy() #下次迭代时Lk-1=Lk
L.append(Lksub1)
i+=1
for i in range(len(L)):
print("frequent item {}:{}".format(i+1,len(L[i])))
return L, support_data
def generate_R(self,dataset, min_support, min_conf):
L,support_data=self.generate_L(dataset,min_support)#根据频繁项集和支持度生成关联规则
rule_list = []#保存满足置信度的规则
sub_set_list = []#该数组保存检查过的频繁项
for i in range(0, len(L)):
for freq_set in L[i]:#遍历Lk
for sub_set in sub_set_list:#sub_set_list中保存的是L1到Lk-1
if sub_set.issubset(freq_set):#检查sub_set是否是freq_set的子集
#检查置信度是否满足要求,是则添加到规则
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in rule_list:
rule_list.append(big_rule)
sub_set_list.append(freq_set)
rule_list = sorted(rule_list,key=lambda x:(x[2]),reverse=True)
return rule_list
if __name__=="__main__":
filename="***************.csv"
min_support=0.03 # 最小支持度0.03
min_conf=0.05 # 最小置信度0.05
size=5 # 频繁项最大大小
current_path=os.getcwd()
if not os.path.exists(current_path+"/log"):
os.mkdir("log")
path=current_path+"/dataset/"+filename
save_path=current_path+"/log/"+filename.split(".")[0]+"_apriori.txt"
data=load_data(path)
# print(data)
apriori=Apriori()
rule_list=apriori.generate_R(data,min_support,min_conf)
save_rule(rule_list,save_path)
FPTree(fp_growth)
#-*- coding: utf-8 -*-
# 参考 https://blog.csdn.net/thebulesky/article/details/109772191
import os
import time
import csv
from tqdm import tqdm
def load_data(path):#根据路径加载数据集
ans=[]#将数据保存到该数组
with open(path,"r") as f:
reader=csv.reader(f)
for row in reader:
data = row[1].strip('{').strip('}').split(',')
row=list(set(data))#去重,排序
row.sort()
ans.append(row)#将添加好的数据添加到数组
return ans#返回处理好的数据集,为二维数组
def save_rule(rule,path):#保存结果到txt文件
with open(path,"w") as f:
f.write("index confidence"+" rules\n")
index=1
for item in rule:
s=" {:<4d} {:.3f} {}=>{}\n".format(index,item[2],str(list(item[0])),str(list(item[1])))
index+=1
f.write(s)
f.close()
print("result saved,path is:{}".format(path))
class Node:
def __init__(self, node_name,count,parentNode):
self.name = node_name
self.count = count
self.nodeLink = None#根据nideLink可以找到整棵树中所有nodename一样的节点
self.parent = parentNode#父亲节点
self.children = {}#子节点{节点名字:节点地址}
class Fp_growth():
def update_header(self,node, targetNode):#更新headertable中的node节点形成的链表
while node.nodeLink != None:
node = node.nodeLink
node.nodeLink = targetNode
def update_fptree(self,items, node, headerTable):#用于更新fptree
if items[0] in node.children:
# 判断items的第一个结点是否已作为子结点
node.children[items[0]].count+=1
else:
# 创建新的分支
node.children[items[0]] = Node(items[0],1,node)
# 更新相应频繁项集的链表,往后添加
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = node.children[items[0]]
else:
self.update_header(headerTable[items[0]][1], node.children[items[0]])
# 递归
if len(items) > 1:
self.update_fptree(items[1:], node.children[items[0]], headerTable)
def create_fptree(self,data_set, min_support,flag=False):#建树主函数
'''
根据data_set创建fp树
header_table结构为
{"nodename":[num,node],..} 根据node.nodelink可以找到整个树中的所有nodename
'''
item_count = {}#统计各项出现次数
for t in data_set:#第一次遍历,得到频繁一项集
for item in t:
if item not in item_count:
item_count[item]=1
else:
item_count[item]+=1
headerTable={}
for k in item_count:#剔除不满足最小支持度的项
if item_count[k] >= min_support:
headerTable[k]=item_count[k]
freqItemSet = set(headerTable.keys())#满足最小支持度的频繁项集
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None] # element: [count, node]
tree_header = Node('head node',1,None)
if flag:
ite=tqdm(data_set)
else:
ite=data_set
for t in ite:#第二次遍历,建树
localD = {}
for item in t:
if item in freqItemSet: # 过滤,只取该样本中满足最小支持度的频繁项
localD[item] = headerTable[item][0] # element : count
if len(localD) > 0:
# 根据全局频数从大到小对单样本排序
order_item = [v[0] for v in sorted(localD.items(), key=lambda x:x[1], reverse=True)]
# 用过滤且排序后的样本更新树
self.update_fptree(order_item, tree_header, headerTable)
return tree_header, headerTable
def find_path(self,node, nodepath):
'''
递归将node的父节点添加到路径
'''
if node.parent != None:
nodepath.append(node.parent.name)
self.find_path(node.parent, nodepath)
def find_cond_pattern_base(self,node_name, headerTable):
'''
根据节点名字,找出所有条件模式基
'''
treeNode = headerTable[node_name][1]
cond_pat_base = {}#保存所有条件模式基
while treeNode != None:
nodepath = []
self.find_path(treeNode, nodepath)
if len(nodepath) > 1:
cond_pat_base[frozenset(nodepath[:-1])] = treeNode.count
treeNode = treeNode.nodeLink
return cond_pat_base
def create_cond_fptree(self,headerTable, min_support, temp, freq_items,support_data):
# 最开始的频繁项集是headerTable中的各元素
freqs = [v[0] for v in sorted(headerTable.items(), key=lambda p:p[1][0])] # 根据频繁项的总频次排序
for freq in freqs: # 对每个频繁项
freq_set = temp.copy()
freq_set.add(freq)
freq_items.add(frozenset(freq_set))
if frozenset(freq_set) not in support_data:#检查该频繁项是否在support_data中
support_data[frozenset(freq_set)]=headerTable[freq][0]
else:
support_data[frozenset(freq_set)]+=headerTable[freq][0]
cond_pat_base = self.find_cond_pattern_base(freq, headerTable)#寻找到所有条件模式基
cond_pat_dataset=[]#将条件模式基字典转化为数组
for item in cond_pat_base:
item_temp=list(item)
item_temp.sort()
for i in range(cond_pat_base[item]):
cond_pat_dataset.append(item_temp)
#创建条件模式树
cond_tree, cur_headtable = self.create_fptree(cond_pat_dataset, min_support)
if cur_headtable != None:
self.create_cond_fptree(cur_headtable, min_support, freq_set, freq_items,support_data) # 递归挖掘条件FP树
def generate_L(self,data_set,min_support):
freqItemSet=set()
support_data={}
tree_header,headerTable=self.create_fptree(data_set,min_support,flag=True)#创建数据集的fptree
#创建各频繁一项的fptree,并挖掘频繁项并保存支持度计数
self.create_cond_fptree(headerTable, min_support, set(), freqItemSet,support_data)
max_l=0
for i in freqItemSet:#将频繁项根据大小保存到指定的容器L中
if len(i)>max_l:max_l=len(i)
L=[set() for _ in range(max_l)]
for i in freqItemSet:
L[len(i)-1].add(i)
for i in range(len(L)):
print("frequent item {}:{}".format(i+1,len(L[i])))
return L,support_data
def generate_R(self,data_set, min_support, min_conf):
L,support_data=self.generate_L(data_set,min_support)
rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set) and freq_set-sub_set in support_data:#and freq_set-sub_set in support_data
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in rule_list:
# print freq_set-sub_set, " => ", sub_set, "conf: ", conf
rule_list.append(big_rule)
sub_set_list.append(freq_set)
rule_list = sorted(rule_list,key=lambda x:(x[2]),reverse=True)
return rule_list
if __name__=="__main__":
filename="****************.csv"
min_support=0.03 #最小支持度25
min_conf=0.05 #最小置信度0.7
spend_time=[]
current_path=os.getcwd()
if not os.path.exists(current_path+"/log"):
os.mkdir("log")
path=current_path+"/dataset/"+filename
save_path=current_path+"/log/"+filename.split(".")[0]+"_fp-tree.txt"
data_set=load_data(path)
fp=Fp_growth()
rule_list = fp.generate_R(data_set, min_support, min_conf)
save_rule(rule_list,save_path)
打赏6.6元
手机端:用系统浏览器访问本链接,打开支付宝完成打赏
订单号示例
1.微信中:截图保存支付宝绿码,支付宝扫码打赏,手动获取;
2.电脑端:使用手机支付宝直接扫绿码,完成打赏,自动获取;