Python数据分析及可视化实例之基于Kmean分析RFM进行用户关怀
发布时间:2021-12-04
付费文章:2.0元
该数据集为用户RFM,付费后可以查看加密内容,获取下载链接,若链接失效,联系微信yeeyea
加载数据
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', None) # 设置显示所有列
df = pd.read_excel('UXFTLB.xls', index_col = 'Id') #读取数据
df.head()R F M Id 1 27 6 232.61 2 3 5 1507.11 3 4 16 817.62 4 3 11 232.81 5 14 7 1913.05
聚类分析
X=1.0*(df - df.mean())/df.std() #数据标准化
X.head()R F M Id 1 0.764186 -0.493579 -1.158711 2 -1.024757 -0.630079 0.622527 3 -0.950217 0.871423 -0.341103 4 -1.024757 0.188922 -1.158432 5 -0.204824 -0.357079 1.189868
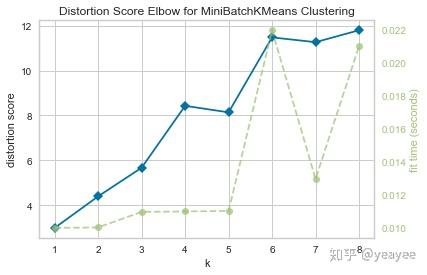
from yellowbrick.cluster import KElbowVisualizer
from sklearn.cluster import MiniBatchKMeans
visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(1,9))
visualizer.fit(X)
visualizer.poof() # 肘部不明显,分为4类
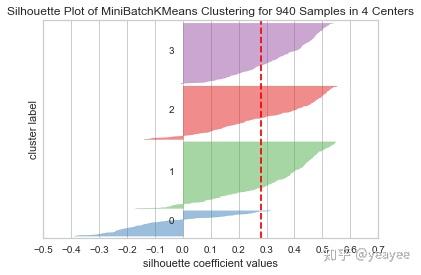
分类轮廓
from yellowbrick.cluster import SilhouetteVisualizer
model = MiniBatchKMeans(4)
visualizer = SilhouetteVisualizer(model)
visualizer.fit(X)
visualizer.poof()
Kmean聚类
from sklearn.cluster import KMeans
model = KMeans(n_clusters = 4, n_jobs = 4, max_iter = 500) #分为k类,并发数4,#聚类最大循环次数500
model.fit(X) #开始聚类
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=500,
n_clusters=4, n_init=10, n_jobs=4, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
#简单打印结果
r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(X.columns) + ['类别成员数'] #重命名表头
print(r)
R F M 类别成员数
0 -0.167313 1.202923 0.187762 308
1 3.551564 -0.256500 0.423271 38
2 -0.138992 -0.681412 -0.802742 351
3 -0.142555 -0.500320 0.855340 243
#详细输出原始数据及其类别
r = pd.concat([df, pd.Series(model.labels_, index = X.index)], axis = 1) #详细输出每个样本对应的类别
r.columns = list(df.columns) + ['类别'] #重命名表头
r.head()R F M 类别 Id 1 27 6 232.61 2 2 3 5 1507.11 3 3 4 16 817.62 0 4 3 11 232.81 2 5 14 7 1913.05 3
res = r[r['类别']==3]
res.head(10)R F M 类别 Id 2 3 5 1507.11 3 5 14 7 1913.05 3 13 17 11 1744.55 3 15 5 7 1713.79 3 22 17 3 1845.34 3 27 4 2 1795.41 3 28 7 12 1786.24 3 34 14 11 1165.68 3 38 1 1 1383.39 3 39 24 8 3280.77 3
打赏2.0元
手机端:用系统浏览器访问本链接,打开支付宝完成打赏
订单号示例
1.微信中:截图保存支付宝绿码,支付宝扫码打赏,手动获取;
2.电脑端:使用手机支付宝直接扫绿码,完成打赏,自动获取;