换脸、换声、口型驱动于一体
发布时间:2024-10-28
免费文章
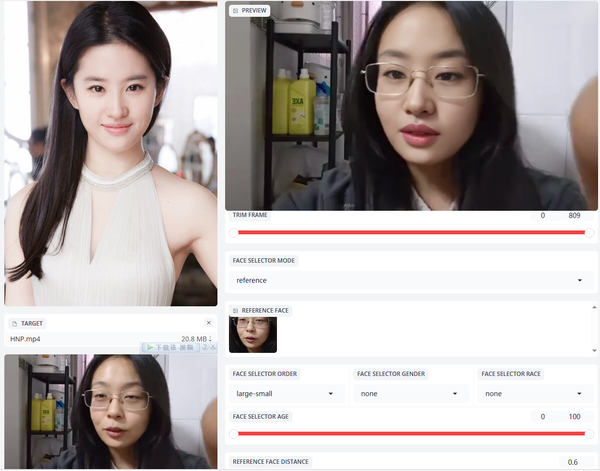
颜值即正义,具体操作流程:
(1)截取视频,面部尽可能少抖动,否则后续换脸,声音驱动都会有BUG;
(2)提取原视频中文字幕,可以转为音频后处理,也可以剪映提取导出;
(3)大模型将中文字幕转换为英文;
(4)声音克隆;
(5)将英文语音与原视频融合(口型不匹配),暂且不要添加英文字母,避免影响到口型驱动;
(6)先采用口型驱动,对(5)视频进行处理,生成口型一致的视频;
(7)采用换脸及加强模型,对(6)视频进行处理;
(8)采用剪映,匹配英文字幕。
按照这个流程生成的视频是相对较好的。以上,除了大模型的调用,由于中英文语言长度差异,因此还涉及到语音的预处理,软件尚无法实现100%自动生成。
感兴趣的小伙伴,可以加微信:civilpy