AdaBoost信用卡精准营销模型
发布时间:2021-12-04
付费文章:2.0元
AdaBoost信用卡精准营销模型
模型搭建
1.读取数据
import pandas as pd
df = pd.read_excel('数据集见本页底.xlsx')
df.head()年龄 月收入(元) 月消费(元) 性别 月消费/月收入 响应 0 30 7275 6062 0 0.833265 1 1 25 17739 13648 0 0.769378 1 2 29 25736 14311 0 0.556069 1 3 23 14162 7596 0 0.536365 1 4 27 15563 12849 0 0.825612 1
2.提取特征变量和目标变量
X = df.drop(columns='响应')
y = df['响应']3.划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)4.模型训练及搭建
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier(random_state=123)
clf.fit(X_train, y_train)
AdaBoostClassifier(algorithm='SAMME.R', base_estimator=None,
learning_rate=1.0, n_estimators=50, random_state=123)2 模型预测及评估
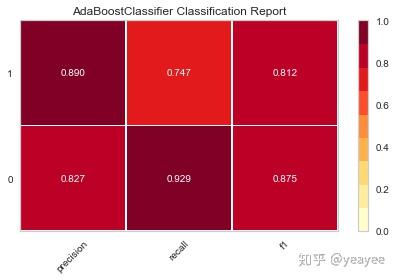
1.精确度
from yellowbrick.classifier import ClassificationReport
def test(model):
visualizer = ClassificationReport(model)
visualizer.fit(X_train, y_train)
print('得分:',visualizer.score(X_test,y_test))
visualizer.poof()
test(clf)
得分: 0.85
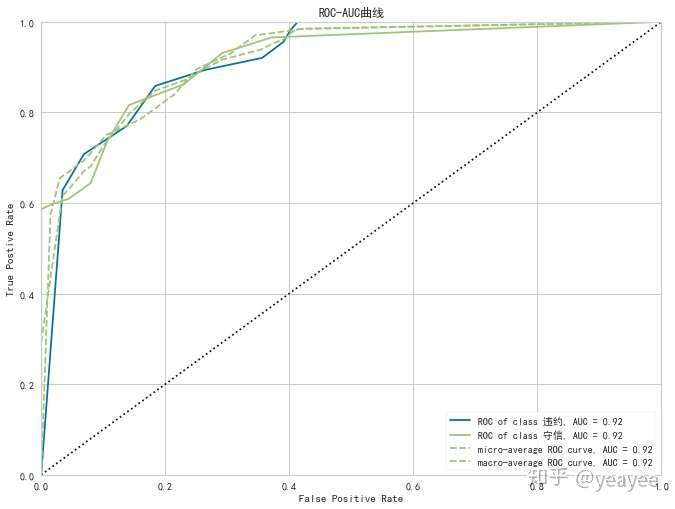
2.ROC-AUC曲线
# 解决中文显示问题
# from yellowbrick.style.rcmod import set_aesthetic
# set_aesthetic(font = 'SimHei')
import matplotlib
matplotlib.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False # 用来正常显示负号
from yellowbrick.classifier import ROCAUC
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=10)
visualizer = ROCAUC(model, classes=["违约", "守信"],size=(800, 600),title="ROC-AUC曲线")
visualizer.fit(X_train, y_train)
visualizer.score(X_test,y_test)
visualizer.poof()
3.特征重要性
from yellowbrick.features.importances import FeatureImportances
viz = FeatureImportances(clf,size=(800, 600),title="AdaBoost算法分类训练特征重要性",xlabel='重要性评分')
viz.fit(X, y)
viz.poof()

4 模型参数(选学)
# # 分类模型,通过如下代码可以查看官方介绍
# from sklearn.ensemble import AdaBoostClassifier
# AdaBoostClassifier?
# # 回归模型,通过如下代码可以查看官方介绍
# from sklearn.ensemble import AdaBoostRegressor
# AdaBoostRegressor?
打赏2.0元
手机端:用系统浏览器访问本链接,打开支付宝完成打赏
订单号示例
1.微信中:截图保存支付宝绿码,支付宝扫码打赏,手动获取;
2.电脑端:使用手机支付宝直接扫绿码,完成打赏,自动获取;