Python数据分析及可视化实例之基于RFM基本概念进行用户关怀
该数据集为用户购买商品的基本数据,付费后可以查看加密内容,获取下载链接,若链接失效,联系微信yeeyea
加载数据
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', None) # 设置显示所有列
trad_flow = pd.read_csv('YFLCDH.csv', encoding='gbk')
# trad_flow.head() # 商品ID、用户ID、时间、价格、状态,状态en查看分类
trad_flow['type_label'].unique() # 商品的4种状态Normal Presented returned_goods Special_offer
array(['正常', '赠送', '退货', '特价'], dtype=object)R最近一次消费 (Recency)
import time
# 先将非标准字符串时间格式化为时间数组,再转换为时间戳便于计算
trad_flow['time'] = trad_flow['time'].map(lambda x: time.mktime(time.strptime(x, '%d%b%y:%H:%M:%S')))
# 查找每个用户ID每个销售类型下的最近时间
R=trad_flow.groupby(['cumid','type'])[['time']].max()
# 转化为透视表
R_trans=pd.pivot_table(R,index='cumid',columns='type',values='time')
# 用最久远的购物时间替换缺失值
R_trans[['Special_offer','returned_goods']] = R_trans[['Special_offer','returned_goods']].apply(lambda x: x.replace(np.nan, min(x)),
axis = 0)
R_trans['R_max'] = R_trans[['Normal','Presented','Special_offer']].apply(lambda x: max(x), axis =1) # 个人近一次交易时间
R_trans.head()type Normal Presented Special_offer returned_goods R_max cumid 10001 1.284699e+09 1.284197e+09 1.255316e+09 1.278766e+09 1.284699e+09 10002 1.276953e+09 1.278129e+09 1.250297e+09 1.252047e+09 1.278129e+09 10003 1.282983e+09 1.280805e+09 1.262435e+09 1.275806e+09 1.282983e+09 10004 1.279534e+09 1.283057e+09 1.254833e+09 1.275571e+09 1.283057e+09 10005 1.277448e+09 1.282127e+09 1.250297e+09 1.270728e+09 1.282127e+09
F消费频率 (Frequency)
# 对购物频率按照用户ID和购物类型进行汇总统计
F=trad_flow.groupby(['cumid','type'])[['transID']].count()
# 转化为透视表
F_trans=pd.pivot_table(F,index='cumid',columns='type',values='transID')
# 用0填补缺失值
F_trans[['Special_offer','returned_goods']] = F_trans[['Special_offer','returned_goods']].fillna(0)
# 将退货的频数转化为负数
F_trans['returned_goods'] = F_trans['returned_goods'].map(lambda x: -x)
# 求每个用户ID的购物总次数
F_trans["F_total"] = F_trans.apply(lambda x: sum(x), axis = 1) # 个人总交易频次
F_trans.head()type Normal Presented Special_offer returned_goods F_total cumid 10001 15.0 8.0 2.0 -2.0 23.0 10002 12.0 5.0 0.0 -1.0 16.0 10003 15.0 8.0 1.0 -1.0 23.0 10004 15.0 12.0 2.0 -1.0 28.0 10005 8.0 5.0 0.0 -1.0 12.0
# F_trans = pd.crosstab(trad_flow['cumid'],trad_flow['type']) # 其中0之为NAN 一行顶三行
# # 将退货的频数转化为负数
# F_trans['returned_goods'] = F_trans['returned_goods'].map(lambda x: -x)
# # 求每个购物ID的购物总次数
# F_trans["F_total"] = F_trans.apply(lambda x: sum(x), axis = 1) # 个人总交易频次
# F_trans.head()M消费金额 (Monetary)
# 对购物金额按照用户ID和购物类型进行汇总统计
M=trad_flow.groupby(['cumid','type'])[['amount']].sum()
# 转化为透视表
M_trans=pd.pivot_table(M,index='cumid',columns='type',values='amount')
# 用0填补缺失值
M_trans[['Special_offer','returned_goods']] = M_trans[['Special_offer','returned_goods']].fillna(0)
# 求每个购物ID的购物总金额
M_trans["M_total"] = M_trans.apply(lambda x: sum(x), axis = 1) # 个人总交易额度
M_trans.head()type Normal Presented Special_offer returned_goods M_total cumid 10001 3608.0 0.0 420.0 -694.0 3334.0 10002 1894.0 0.0 0.0 -242.0 1652.0 10003 3503.0 0.0 156.0 -224.0 3435.0 10004 2979.0 0.0 373.0 -40.0 3312.0 10005 2368.0 0.0 0.0 -249.0 2119.0
# M_trans = pd.crosstab(trad_flow['cumid'],trad_flow['type'],values=trad_flow['amount'],aggfunc='sum').fillna(0)
# M_trans["M_total"] = M_trans.apply(lambda x: sum(x), axis = 1) # 个人总交易额度
# M_trans.head()合并数据
# 合并表
RFM = pd.concat([R_trans['R_max'],F_trans['F_total'],M_trans['M_total']], axis = 1)
# RFM三个维度等宽分箱打分
RFM['R_score'] = pd.cut(RFM.R_max,3,labels = [1,2,3])
RFM['F_score'] = pd.cut(RFM.F_total,3,labels = [1,2,3])
RFM['M_score'] = pd.cut(RFM.M_total,3,labels = [1,2,3])
RFM.head() # 3*3*3R_max F_total M_total R_score F_score M_score cumid 10001 1.284699e+09 23 3334.0 3 2 2 10002 1.278129e+09 16 1652.0 1 1 1 10003 1.282983e+09 23 3435.0 3 2 2 10004 1.283057e+09 28 3312.0 3 3 2 10005 1.282127e+09 12 2119.0 2 1 1
用户分类
# RFM各三类,总共有27种组合,为方便营销简化分类为8种
def score_label(a,b,c):
'''
a: 'R_score'
b: 'F_score'
c: 'M_score'
'''
if a == 3 and b == 3 and c == 3:
return '重要价值客户'
elif a == 3 and (b in [1,2]) and c == 3:
return '重要发展客户'
elif (a in [1,2]) and b == 3 and c == 3:
return '重要保持客户'
elif (a in [1,2]) and (b in [1,2]) and c == 3:
return '重要挽留客户'
elif a == 3 and b == 3 and (c in [1,2]):
return '一般价值客户'
elif a == 3 and (b in [1,2]) and (c in [1,2]):
return '一般发展客户'
elif (a in [1,2]) and b == 3 and (c in [1,2]):
return '一般保持客户'
elif (a in [1,2]) and (b in [1,2]) and (c in [1,2]):
return '一般挽留客户'
# 为每个购物ID贴标签
RFM['Label'] = RFM[['R_score', 'F_score', 'M_score']].apply(lambda x: score_label(x[0],x[1],x[2]), axis = 1)
RFM.head() # 可以用Sklearn分类算法进行训练R_max F_total M_total R_score F_score M_score Label cumid 10001 1.284699e+09 23 3334.0 3 2 2 一般发展客户 10002 1.278129e+09 16 1652.0 1 1 1 一般挽留客户 10003 1.282983e+09 23 3435.0 3 2 2 一般发展客户 10004 1.283057e+09 28 3312.0 3 3 2 一般价值客户 10005 1.282127e+09 12 2119.0 2 1 1 一般挽留客户
对特价敏感的用户
M_trans.head()type Normal Presented Special_offer returned_goods M_total cumid 10001 3608.0 0.0 420.0 -694.0 3334.0 10002 1894.0 0.0 0.0 -242.0 1652.0 10003 3503.0 0.0 156.0 -224.0 3435.0 10004 2979.0 0.0 373.0 -40.0 3312.0 10005 2368.0 0.0 0.0 -249.0 2119.0
M_trans.columns = ['常规', '赠品', '特价', '退货','总额']
M_trans['特价']= M_trans['特价'].fillna(0)
M_trans.head()常规 赠品 特价 退货 总额 cumid 10001 3608.0 0.0 420.0 -694.0 3334.0 10002 1894.0 0.0 0.0 -242.0 1652.0 10003 3503.0 0.0 156.0 -224.0 3435.0 10004 2979.0 0.0 373.0 -40.0 3312.0 10005 2368.0 0.0 0.0 -249.0 2119.0
M_trans['特价购买率']=M_trans['特价']/(M_trans['特价']+M_trans['常规'])
M_rank=M_trans.sort_values('特价',ascending=False,na_position='last')
M_rank['特价偏好分类'] = pd.qcut( M_rank['特价购买率'], 4) # 这里以age_oldest_tr字段等宽分为4段
M_rank.shape
(1200, 7)
M_rank['cumid'] = M_rank.index
M_rank.groupby('特价偏好分类').count() # 将用户分为4个等级常规 赠品 特价 退货 总额 特价购买率 cumid 特价偏好分类 (-0.001, 0.00431] 300 300 300 300 300 300 300 (0.00431, 0.0508] 300 300 300 300 300 300 300 (0.0508, 0.0972] 300 300 300 300 300 300 300 (0.0972, 0.532] 300 300 300 300 300 300 300
M_rank[ M_rank['特价购买率']>0.0972]['cumid'].head(10) # 重点关注的用户,前十名
cumid
40158 40158
10128 10128
10110 10110
10187 10187
10052 10052
30033 30033
10151 10151
20285 20285
20090 20090
30064 30064
Name: cumid, dtype: int64
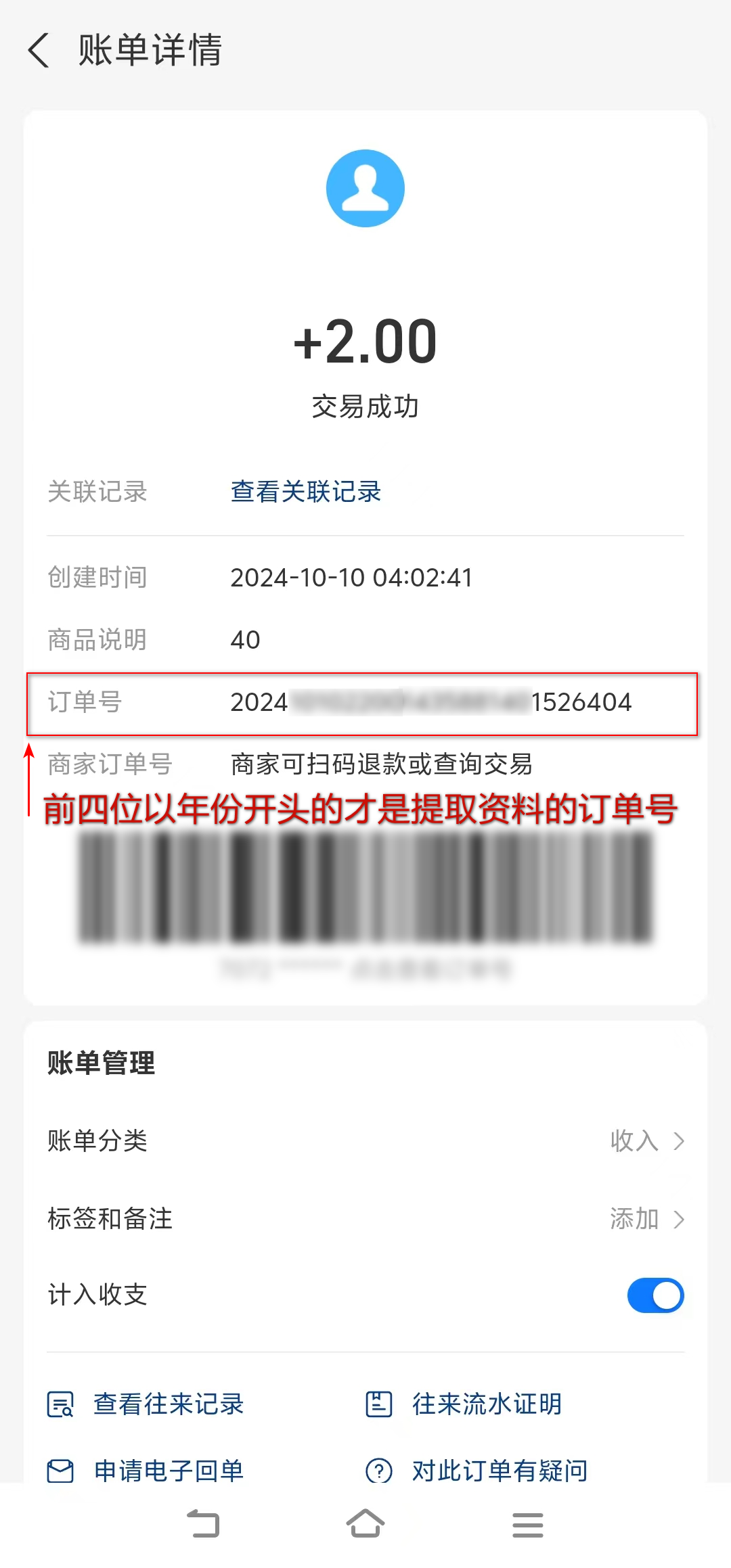
手机端:用系统浏览器访问本链接,打开支付宝完成打赏
订单号示例
1.微信中:截图保存支付宝绿码,支付宝扫码打赏,手动获取;
2.电脑端:使用手机支付宝直接扫绿码,完成打赏,自动获取;