Python量化学习-获取证券数据的几种方式
发布时间:2021-12-03
公开文章
I am not a designer nor a coder. I'm just a guy with a point-of-view and a computer. 翻译:俺不是码畜,俺只是一条对着电脑有点想法的图狗。
经验
- 一旦遇到问题,请过滤掉专家的意见,只采纳跟你有类似经历的人的意见。
- 做好最坏的打算,以最积极的心态去面对,而不是逃避。
- 学不学编程,完全取决于是否想学,其他的别多想。
- 种一棵树最好的时间是十年前,其次是现在。
网易财经
import requests
from lxml import etree
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
}
def parse_url(url):
response = requests.get(url,headers=headers)
if response.status_code == 200:
return etree.HTML(response.content)
return False
def get_date(response):
# 得到股票代码,开始和结束的日期
start_date = ''.join(response.xpath('//input[@name="date_start_type"]/@value')[0].split('-'))
end_date = ''.join(response.xpath('//input[@name="date_end_type"]/@value')[0].split('-'))
code = response.xpath('//h1[@class="name"]/span/a/text()')[0]
return code,start_date,end_date
def download(code,start_date, end_date):
download_url = "http://quotes.money.163.com/service/chddata.html?code=1"+code+"&start="+start_date+"&end="+end_date+\
"&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP"
print(download_url)
data = requests.get(download_url,headers=headers)
f = open(code + '.csv', 'wb')
for chunk in data.iter_content(chunk_size=10000):
if chunk:
f.write(chunk)
print('股票---',code,'历史数据正在下载')
download(code,'20210401', end_date)
新浪财经API
from urllib import request
import json
import pandas as pd股票
def get_stock_data(id, scale, data_len):
'''
symnol = 股票代码
scale = 5,15,30,60
datalen = 获取数据长度,最大1023
'''
# 拼接API的url
url = 'http://quotes.sina.cn/cn/api/json_v2.php/CN_MarketDataService.getKLineData?symbol={0}&scale={1}&datalen={2}'.format(id, scale, data_len)
# 发起请求
req = request.Request(url)
# 获取响应
rsp = request.urlopen(req)
# 读取响应结果
res = rsp.read()
# 将json序列转换为Python对象
res_json = json.loads(res)
# bar列表
bar_list = []
# 将结果逆序
res_json.reverse()
# 遍历列表
for dict in res_json:
bar = {}
bar['date'] = dict['day']
bar['open'] = float(dict['open'])
bar['high'] = float(dict['high'])
bar['low'] = float(dict['low'])
bar['close'] = float(dict['close'])
bar['vol'] = int(dict['volume'])
bar_list.append(bar)
# 将结果转换为DataFrame对象
df = pd.DataFrame(data=bar_list)
return df
df = get_stock_data('sz002415', 30, 30)
df.head()
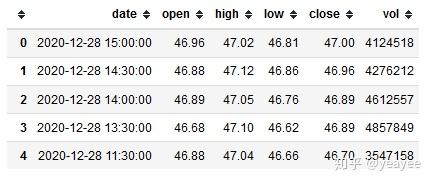
期货
def get_future_data(id, scale):
# 拼接API的url
url = 'http://stock2.finance.sina.com.cn/futures/api/json.php/IndexService.getInnerFuturesMiniKLine{0}m?symbol={1}'.format(scale, id)
# 发起请求
req = request.Request(url)
# 获取响应
rsp = request.urlopen(req)
# 读取响应结果
res = rsp.read()
# 将json序列转换为Python对象
res_json = json.loads(res)
# bar列表
# print(res_json)
bar_list = []
# 将结果逆序
res_json.reverse()
# 遍历列表
for line in res_json:
bar = {}
bar['date'] = line[0]
bar['open'] = float(line[1])
bar['high'] = float(line[2])
bar['low'] = float(line[3])
bar['close'] = float(line[4])
bar['vol'] = int(line[5])
bar_list.append(bar)
# 将结果转换为DataFrame对象
df = pd.DataFrame(data=bar_list)
return df
df = get_future_data('rb1910', 5)
df.head()
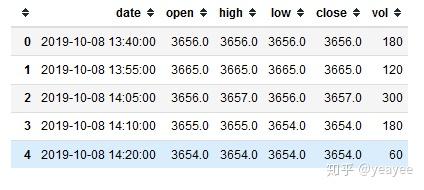
其他接口:https://blog.csdn.net/afgasdg/article/details/86071921
baostock获取沪深股票历史数据(开放)
http://baostock.com/baostock/index.php
import baostock as bs
import pandas as pd
#### 登陆系统 ####
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
login success!
login respond error_code:0
login respond error_msg:success
#### 获取历史K线数据 ####
# 详细指标参数,参见“历史行情指标参数”章节
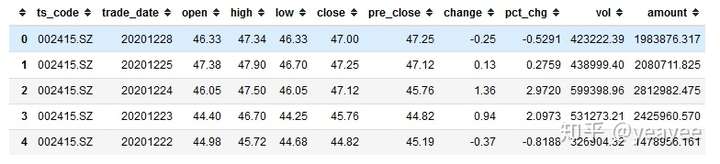
rs = bs.query_history_k_data_plus("sz.002415",
"date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,peTTM,pbMRQ,psTTM,pcfNcfTTM,isST",
start_date='2020-01-01', end_date='2020-12-28',
frequency="d", adjustflag="3") #frequency="d"取日k线,adjustflag="3"默认不复权
#### 打印结果集 ####
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
#### 结果集输出到csv文件 ####
# result.to_csv("D:/history_k_data.csv", encoding="gbk", index=False)
# print(result)
result.tail()

tushare获取证券数据(高级权限需要积分)
import tushare as ts
pro = ts.pro_api('****************************')历史行情
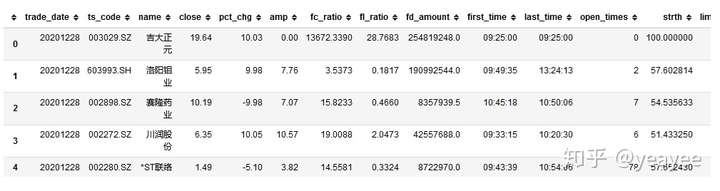
涨跌数据
df = pro.limit_list() # 获取涨跌数据,需要权限
df.head()