数据挖掘之决策树分类
发布时间:2021-12-03
公开文章
import numpy as np
import pandas as pd
from sklearn import tree
input_file = "数据集见页底链接.csv" # 预测是否雇佣
df = pd.read_csv(input_file, header = 0)
df.head()| Years Experience | Employed? | Previous employers | Level of Education | Top-tier school | Interned | Hired |
|---|
# 比较骚的操作
d = {'Y': 1, 'N': 0}
df['Hired'] = df['Hired'].map(d)
df['Employed?'] = df['Employed?'].map(d)
df['Top-tier school'] = df['Top-tier school'].map(d)
df['Interned'] = df['Interned'].map(d)
d = {'BS': 0, 'MS': 1, 'PhD': 2}
df['Level of Education'] = df['Level of Education'].map(d)
df.head()| Years Experience | Employed? | Previous employers | Level of Education | Top-tier school | Interned | Hired |
|---|
features = list(df.columns[:-1])
features
['Years Experience',
'Employed?',
'Previous employers',
'Level of Education',
'Top-tier school',
'Interned']
y = df["Hired"] # 标签
X = df[features] # 数据集
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,y)
import os
# 安装过程中可能出现错误:InvocationException: GraphViz’s executables not found
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/' #注意修改路径
from IPython.display import Image
from sklearn.externals.six import StringIO
import pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=features) # clff分类器
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
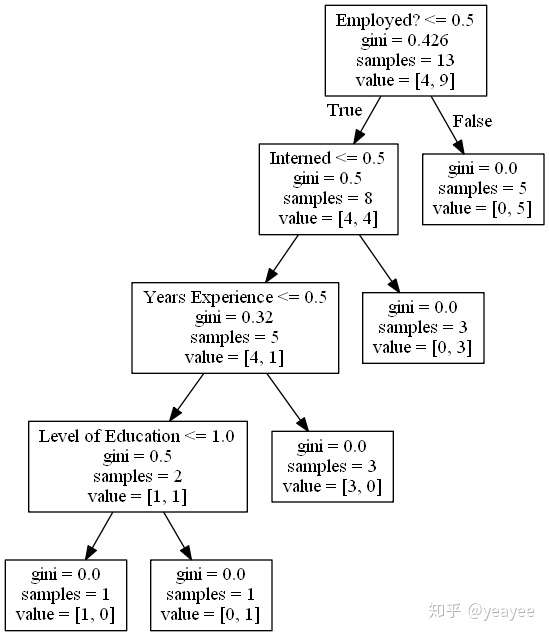
#预测具有10年工作经验的是否被聘用
print (clf.predict([[10, 1, 4, 0, 0, 0]]))
#预测失业10年是否被聘用
print (clf.predict([[10, 0, 4, 0, 0, 0]]))
[1]
[0]
from sklearn.ensemble import RandomForestClassifier
# 用随机森林进行预测
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, y)
#预测具有10年工作经验的是否被聘用
print (clf.predict([[10, 1, 4, 0, 0, 0]]))
#预测失业10年是否被聘用
print (clf.predict([[10, 0, 4, 0, 0, 0]]))
[1]
[0]
在可视化过程中会遇到一些坑。同样决策树的计算原理,自行搜索。