数据挖掘之训练集、测试集
发布时间:2021-12-03
公开文章
Jupiter代码原味展示:
%matplotlib inline
import numpy as np
from pylab import *
np.random.seed(2)
pageSpeeds = np.random.normal(3.0, 1.0, 100)
purchaseAmount = np.random.normal(50.0, 30.0, 100) / pageSpeeds
scatter(pageSpeeds, purchaseAmount)
<matplotlib.collections.PathCollection at 0x1c4457ae940>
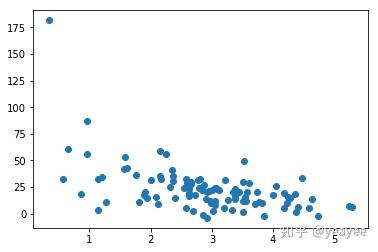
trainX = pageSpeeds[:80]
testX = pageSpeeds[80:]
trainY = purchaseAmount[:80]
testY = purchaseAmount[80:]
scatter(trainX, trainY)
<matplotlib.collections.PathCollection at 0x1c445b795c0>
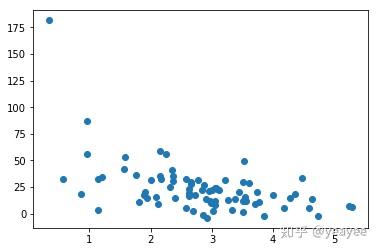
scatter(testX, testY)
<matplotlib.collections.PathCollection at 0x1c445be8320>
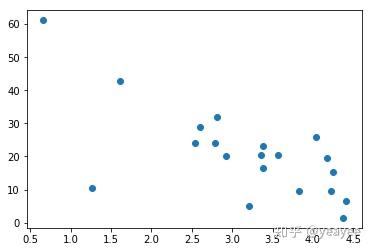
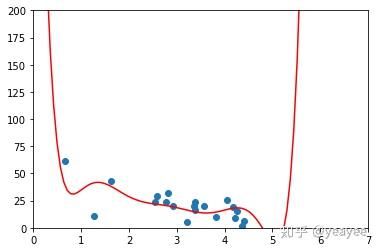
x = np.array(trainX)
y = np.array(trainY)
p4 = np.poly1d(np.polyfit(x, y, 8))
import matplotlib.pyplot as plt
xp = np.linspace(0, 7, 100)
axes = plt.axes()
axes.set_xlim([0,7])
axes.set_ylim([0, 200])
plt.scatter(x, y)
plt.plot(xp, p4(xp), c='r')
plt.show()
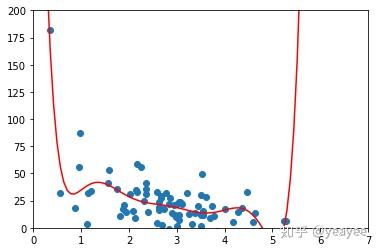
testx = np.array(testX)
testy = np.array(testY)
axes = plt.axes()
axes.set_xlim([0,7])
axes.set_ylim([0, 200])
plt.scatter(testx, testy)
plt.plot(xp, p4(xp), c='r')
plt.show()
from sklearn.metrics import r2_score
r2 = r2_score(testy, p4(testx))
print(r2)
0.30018168612
from sklearn.metrics import r2_score
r2 = r2_score(np.array(trainY), p4(np.array(trainX)))
print(r2)
0.642706951469直观看起来似乎没毛病,再来看看相关指数r2(取值越大,意味着残差平方和越小,也就是模型的拟合效果越好)。过拟合就此产生了,如何解决,且看下回解说~