数据预处理:标准化,归一化,正则化
1. 归一化(Normalization)
归一化 (Resaling) 一般是将数据映射到指定的范围,用于去除不同维度放入量纲以及量纲单位。常见的映射范围有 [ 0, -1 ] 和 [ -1, 1],最常见的归一化方法就是 Min-Max 归一化:

涉及距离度量、协方差计算时不能应用这种方法,因为这种线性等比例缩放无法消除量纲对方差、协方差的影响。
min_max_scaler = preprocessing.MinMaxScaler()
data_T_minmax = min_max_scaler.fit_transform(data.T)
data_minmax = data_T_minmax.T
2. 标准化(Standardization)
最常见的标准化方法:Z-Score 标准化。
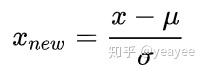
其中μ是样本均值,σ是样本数据的标准差。
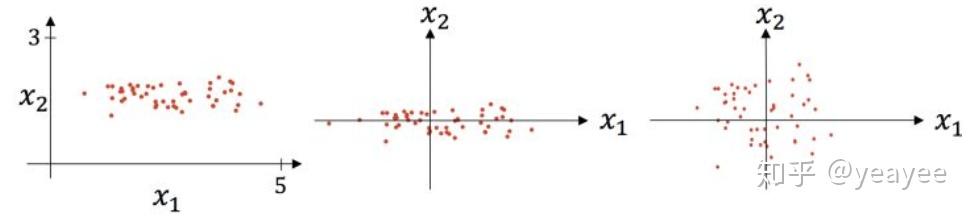
上图则是一个散点序列的标准化过程:原图 -> 减去均值 -> 除以标准差。
显而易见,变成了一个均值为 0 ,方差为 1 的分布,下图通过 Cost 函数让我们更好的理解标准化的作用。
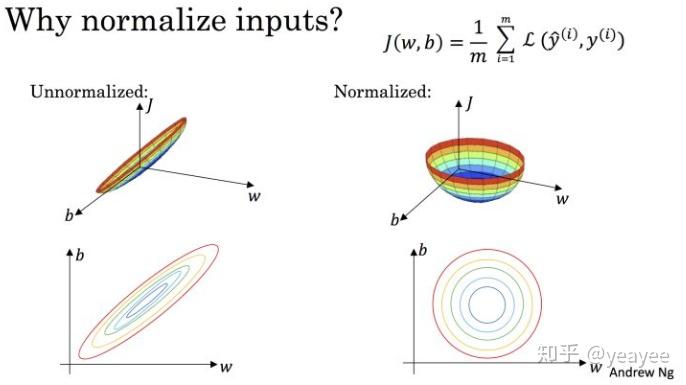
机器学习的目标无非就是不断优化损失函数,使其值最小。在上图中,J (w, b) 就是我们要优化的目标函数。
我们不难看出,标准化后可以更加容易地得出最优参数 w 和 b 以及计算出 J (w, b) 的最小值,从而达到加速收敛的效果。
注:上图来源于 Andrew Ng 的课程讲义
from sklearn import preprocessing
import pandas as pd
import numpy as np
mean=[4,3]
cov=[[2.0,5.],[1.,1.]]
x=np.random.multivariate_normal(mean,cov,7)
data=pd.DataFrame(x)
scaler = preprocessing.StandardScaler().fit(data.T) #对行做标准化处理
data_T_scale = scaler.transform(data.T)
data_scale = data_T_scale.transpose()3. 正则化(Regularization)
正则化主要用于避免过拟合的产生和减少网络误差。
正则化一般具有如下形式:

其中,第1项是经验风险,第2项是正则项,λ>=0 为调整两者之间关系的系数。
第1项是经验风险较小的模型可能较复杂(有多个非零参数),这时,第2项的模型度会较好。
常见的正则项有L1正则和L2正则,其中L2正则的控制过拟合的效果比L1正则的好。
正则化的作用是选择经验风险与模型复杂度同时较小的模型。
Lp范数:LpLp正则的L是指LpLp范数,其定义是:

在机器学习中,若使用了∣∣w∣∣p∣∣w∣∣p作为正则项,我们则说该机器学习引入了Lp正则项。
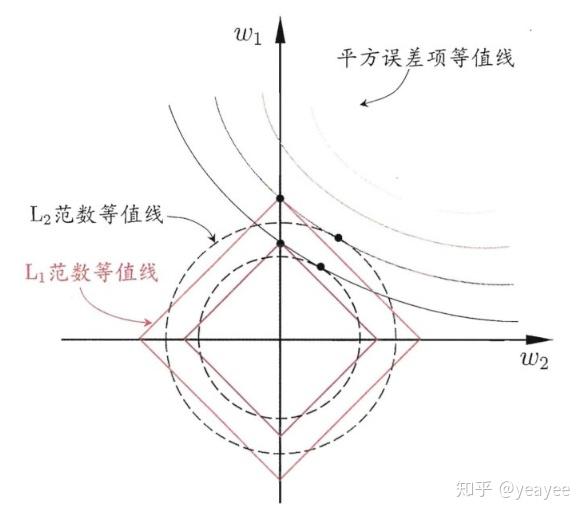
L1 正则 Lasso regularizer
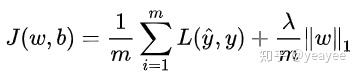
凸函数,不是处处可微
得到的是稀疏解(最优解常出现在顶点上,且顶点上的w只有很少的元素是非零的)
L2 正则 Ridge Regularizer / Weight Decay
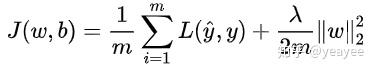
凸函数,处处可微;易于优化。
normalizer = preprocessing.Normalizer(copy=True, norm='l2').fit(data.T)
data_T_normalize=normalizer.transform(data.T) ————————————————
二元化 binarize
import warnings
warnings.filterwarnings("ignore")
from sklearn.preprocessing import Binarizer
def test_Binarizer():
'''
测试 Binarizer 的用法
:return: None
'''
X=[[1,2,3,4,5],
[5,4,3,2,1],
[3,3,3,3,3,],
[1,1,1,1,1] ]
print("before transform:\n",X)
binarizer=Binarizer(threshold=2.5) # 小于2.5为0,大于2.5为1
print("after transform:\n",binarizer.transform(X))
test_Binarizer() # 调用 test_Binarizer
before transform:
[[1, 2, 3, 4, 5], [5, 4, 3, 2, 1], [3, 3, 3, 3, 3], [1, 1, 1, 1, 1]]
after transform:
[[0 0 1 1 1]
[1 1 1 0 0]
[1 1 1 1 1]
[0 0 0 0 0]]独热码编码OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
def test_OneHotEncoder():
'''
测试 OneHotEncoder 的用法
:return: None
'''
X=[ [1,2,3,4,5],
[5,4,3,2,1],
[3,3,3,3,3,],
[1,1,1,1,1] ]
print("before transform:",X)
encoder=OneHotEncoder(sparse=False)
encoder.fit(X)
print("active_features_:",encoder.active_features_)
print("feature_indices_:",encoder.feature_indices_)
print("n_values_:",encoder.n_values_)
print("after transform:\n",encoder.transform(X))
test_OneHotEncoder() # 调用 test_OneHotEncoder
before transform: [[1, 2, 3, 4, 5], [5, 4, 3, 2, 1], [3, 3, 3, 3, 3], [1, 1, 1, 1, 1]]
active_features_: [ 1 3 5 7 8 9 10 12 14 16 17 18 19 21 23 25]
feature_indices_: [ 0 6 11 15 20 26]
n_values_: [6 5 4 5 6]
after transform:
[[1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 1. 0. 0.]
[0. 1. 0. 0. 0. 1. 0. 0. 1. 0. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 1. 0. 0. 0. 1. 0. 1. 0. 0. 0. 1. 0. 0.]]数据标准化standardize
from sklearn.preprocessing import MinMaxScaler,MaxAbsScaler,StandardScaler
def test_MinMaxScaler():
'''
测试 MinMaxScaler 的用法
:return: None
'''
X=[ [1,5,1,2,10],
[2,6,3,2,7],
[3,7,5,6,4,],
[4,8,7,8,1] ]
print("before transform:",X)
scaler=MinMaxScaler(feature_range=(0,2))
scaler.fit(X)
print("min_ is :",scaler.min_)
print("scale_ is :",scaler.scale_)
print("data_max_ is :",scaler.data_max_)
print("data_min_ is :",scaler.data_min_)
print("data_range_ is :",scaler.data_range_)
print("after transform:\n",scaler.transform(X))
test_MinMaxScaler()
before transform: [[1, 5, 1, 2, 10], [2, 6, 3, 2, 7], [3, 7, 5, 6, 4], [4, 8, 7, 8, 1]]
min_ is : [-0.66666667 -3.33333333 -0.33333333 -0.66666667 -0.22222222]
scale_ is : [0.66666667 0.66666667 0.33333333 0.33333333 0.22222222]
data_max_ is : [ 4. 8. 7. 8. 10.]
data_min_ is : [1. 5. 1. 2. 1.]
data_range_ is : [3. 3. 6. 6. 9.]
after transform:
[[0. 0. 0. 0. 2. ]
[0.66666667 0.66666667 0.66666667 0. 1.33333333]
[1.33333333 1.33333333 1.33333333 1.33333333 0.66666667]
[2. 2. 2. 2. 0. ]]
def test_MaxAbsScaler():
'''
测试 MaxAbsScaler 的用法
:return: None
'''
X=[ [1,5,1,2,10],
[2,6,3,2,7],
[3,7,5,6,4,],
[4,8,7,8,1] ]
print("before transform:",X)
scaler=MaxAbsScaler()
scaler.fit(X)
print("scale_ is :",scaler.scale_)
print("max_abs_ is :",scaler.max_abs_)
print("after transform:\n",scaler.transform(X))
test_MaxAbsScaler()
before transform: [[1, 5, 1, 2, 10], [2, 6, 3, 2, 7], [3, 7, 5, 6, 4], [4, 8, 7, 8, 1]]
scale_ is : [ 4. 8. 7. 8. 10.]
max_abs_ is : [ 4. 8. 7. 8. 10.]
after transform:
[[0.25 0.625 0.14285714 0.25 1. ]
[0.5 0.75 0.42857143 0.25 0.7 ]
[0.75 0.875 0.71428571 0.75 0.4 ]
[1. 1. 1. 1. 0.1 ]]
def test_StandardScaler():
'''
测试 StandardScaler 的用法
:return: None
'''
X=[ [1,5,1,2,10],
[2,6,3,2,7],
[3,7,5,6,4,],
[4,8,7,8,1] ]
print("before transform:",X)
scaler=StandardScaler()
scaler.fit(X)
print("scale_ is :",scaler.scale_)
print("mean_ is :",scaler.mean_)
print("var_ is :",scaler.var_)
print("after transform:\n",scaler.transform(X))
test_StandardScaler()
before transform: [[1, 5, 1, 2, 10], [2, 6, 3, 2, 7], [3, 7, 5, 6, 4], [4, 8, 7, 8, 1]]
scale_ is : [1.11803399 1.11803399 2.23606798 2.59807621 3.35410197]
mean_ is : [2.5 6.5 4. 4.5 5.5]
var_ is : [ 1.25 1.25 5. 6.75 11.25]
after transform:
[[-1.34164079 -1.34164079 -1.34164079 -0.96225045 1.34164079]
[-0.4472136 -0.4472136 -0.4472136 -0.96225045 0.4472136 ]
[ 0.4472136 0.4472136 0.4472136 0.57735027 -0.4472136 ]
[ 1.34164079 1.34164079 1.34164079 1.34715063 -1.34164079]]数据正则化Normalizer
from sklearn.preprocessing import Normalizer
def test_Normalizer():
'''
测试 Normalizer 的用法
:return: None
'''
X=[ [1,2,3,4,5],
[5,4,3,2,1],
[1,3,5,2,4,],
[2,4,1,3,5] ]
print("before transform:",X)
normalizer=Normalizer(norm='l2') # L2范式
print("after transform:\n",normalizer.transform(X))
test_Normalizer()
before transform: [[1, 2, 3, 4, 5], [5, 4, 3, 2, 1], [1, 3, 5, 2, 4], [2, 4, 1, 3, 5]]
after transform:
[[0.13483997 0.26967994 0.40451992 0.53935989 0.67419986]
[0.67419986 0.53935989 0.40451992 0.26967994 0.13483997]
[0.13483997 0.40451992 0.67419986 0.26967994 0.53935989]
[0.26967994 0.53935989 0.13483997 0.40451992 0.67419986]]