Python数据分析及可视化实例之银行信用卡违约预测
发布时间:2023-06-04
付费文章:2.0元
Talk is cheap
加载数据
import pandas as pd
df=pd.read_excel('LRGWFB.xls')
df.head()年龄 教育 工龄 地址 收入 负债率 信用卡负债 其他负债 违约 0 41 3 17 12 176 9.3 11.359392 5.008608 1 1 27 1 10 6 31 17.3 1.362202 4.000798 0 2 40 1 15 14 55 5.5 0.856075 2.168925 0 3 41 1 15 14 120 2.9 2.658720 0.821280 0 4 24 2 2 0 28 17.3 1.787436 3.056564 1
是否有空值
df.isnull().any()
年龄 False
教育 False
工龄 False
地址 False
收入 False
负债率 False
信用卡负债 False
其他负债 False
违约 False
dtype: bool目标集分类
df['违约'].unique()
array([1, 0], dtype=int64)训练集、目标集分割
X, y = df.iloc[:,1:-1],df.iloc[:,-1]特征相关性
classes = X.columns.tolist()
classes
['教育', '工龄', '地址', '收入', '负债率', '信用卡负债', '其他负债']
from yellowbrick.features import Rank2D
visualizer = Rank2D(algorithm='pearson',size=(800, 600),title="7特征向量的皮尔森相关系数")
visualizer.fit(X, y)
visualizer.transform(X)
visualizer.poof()
E:\Anaconda3\lib\site-packages\yellowbrick\features\rankd.py:262: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
X = X.as_matrix()

特征重要性
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.features.importances import FeatureImportances
model = RandomForestClassifier(n_estimators=10)
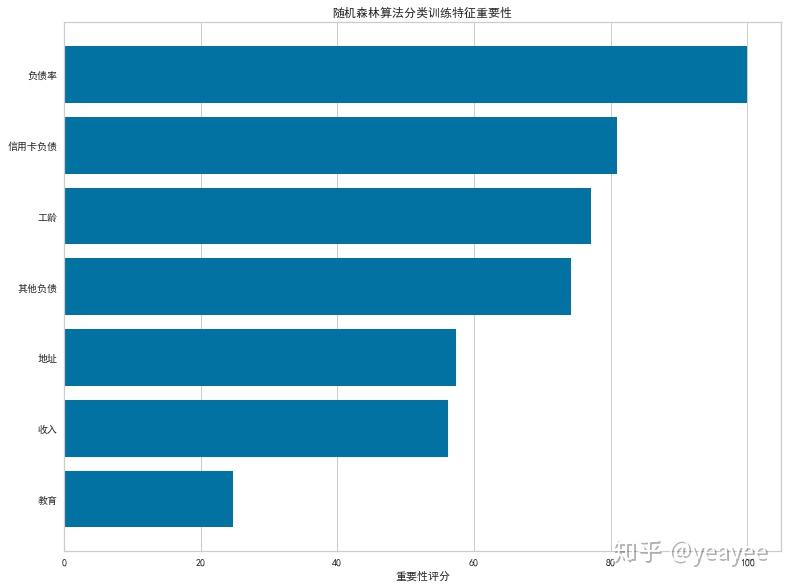
viz = FeatureImportances(model,size=(800, 600),title="随机森林算法分类训练特征重要性",xlabel='重要性评分')
viz.fit(X, y)
viz.poof()
分类报告
训练集、测试集分割
from sklearn.model_selection import train_test_split as tts
X_train, X_test, y_train, y_test = tts(X, y, test_size =0.2, random_state=10)分类结果报告
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import ClassificationReport
model = RandomForestClassifier(n_estimators=10)
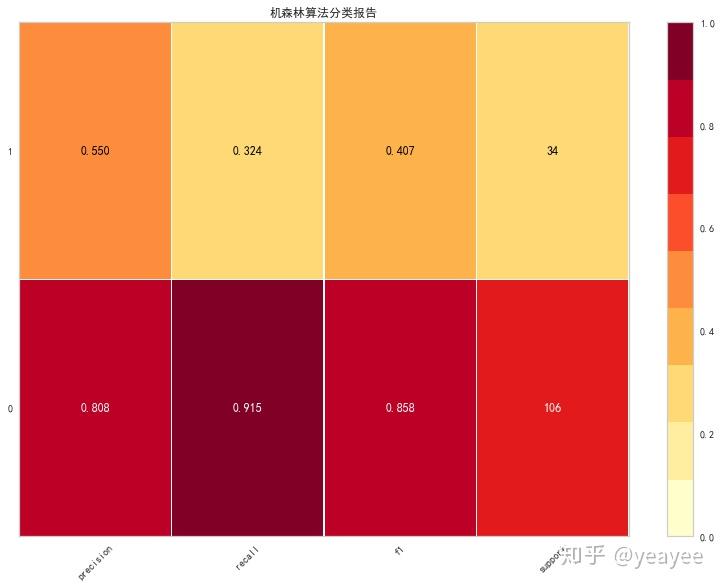
visualizer = ClassificationReport(model, support=True,size=(800, 600),title="机森林算法分类报告")
visualizer.fit(X_train.values, y_train)
print('得分:',visualizer.score(X_test.values, y_test))
visualizer.poof()
得分: 0.7714285714285715
持久化保存
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=10)
model.fit(X_train.values, y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
from sklearn.externals import joblib
joblib.dump(model,'model.pickle') #保存
['model.pickle']载入训练模型
model = joblib.load('model.pickle') #载入
model.predict(X_test) # 输出每组数据的预测结果的标签值
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0,
1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 1, 0, 0, 0, 0], dtype=int64)
model.predict_proba(X_test) # 输出的是二维矩阵 ,第i行j列表示测试数据第i行测试数据在每个label上的概率
array([[1. , 0. ],
[0.9, 0.1],
[0.8, 0.2],
[1. , 0. ],
[0.9, 0.1],
[1. , 0. ],
[0.5, 0.5],
[0.8, 0.2],
[0.9, 0.1],
[1. , 0. ],
[0.4, 0.6],
[1. , 0. ],
[0.6, 0.4],
[0.3, 0.7],
[1. , 0. ],
[0.6, 0.4],
[0.9, 0.1],
[0.7, 0.3],
[1. , 0. ],
[0.9, 0.1],
[0.4, 0.6],
[0.4, 0.6],
[0.5, 0.5],
[1. , 0. ],
[0.8, 0.2],
[1. , 0. ],
[0.9, 0.1],
[0.5, 0.5],
[0.1, 0.9],
[0.9, 0.1],
[0.8, 0.2],
[0.6, 0.4],
[0.8, 0.2],
[0.9, 0.1],
[0.7, 0.3],
[1. , 0. ],
[0.2, 0.8],
[0.9, 0.1],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0.9, 0.1],
[0.4, 0.6],
[0.7, 0.3],
[0.4, 0.6],
[0.9, 0.1],
[0.5, 0.5],
[0.1, 0.9],
[1. , 0. ],
[1. , 0. ],
[0.8, 0.2],
[0.7, 0.3],
[1. , 0. ],
[0.5, 0.5],
[0.8, 0.2],
[0.7, 0.3],
[0.9, 0.1],
[0.8, 0.2],
[0.3, 0.7],
[0.9, 0.1],
[1. , 0. ],
[0.9, 0.1],
[0.9, 0.1],
[0.9, 0.1],
[0.8, 0.2],
[0.9, 0.1],
[1. , 0. ],
[0.9, 0.1],
[0.4, 0.6],
[0.5, 0.5],
[0.9, 0.1],
[0.8, 0.2],
[0.6, 0.4],
[0.8, 0.2],
[1. , 0. ],
[1. , 0. ],
[0.8, 0.2],
[1. , 0. ],
[0.9, 0.1],
[0.6, 0.4],
[1. , 0. ],
[1. , 0. ],
[0.7, 0.3],
[1. , 0. ],
[0.8, 0.2],
[1. , 0. ],
[0.3, 0.7],
[0.9, 0.1],
[0.7, 0.3],
[0.5, 0.5],
[0.4, 0.6],
[1. , 0. ],
[0.9, 0.1],
[0.8, 0.2],
[0.8, 0.2],
[0.9, 0.1],
[0.8, 0.2],
[0.2, 0.8],
[0.7, 0.3],
[0.7, 0.3],
[0.4, 0.6],
[0.6, 0.4],
[0.7, 0.3],
[0.8, 0.2],
[1. , 0. ],
[0.5, 0.5],
[0.8, 0.2],
[1. , 0. ],
[0.9, 0.1],
[0.5, 0.5],
[0.8, 0.2],
[0.6, 0.4],
[0.8, 0.2],
[0.9, 0.1],
[0.9, 0.1],
[0.6, 0.4],
[0.8, 0.2],
[0.9, 0.1],
[0.1, 0.9],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0.9, 0.1],
[0.6, 0.4],
[1. , 0. ],
[0.8, 0.2],
[0.8, 0.2],
[0.7, 0.3],
[0.9, 0.1],
[0.9, 0.1],
[0.5, 0.5],
[1. , 0. ],
[0.2, 0.8],
[0.9, 0.1],
[0.4, 0.6],
[0.2, 0.8],
[0.8, 0.2],
[1. , 0. ],
[0.8, 0.2],
[0.8, 0.2]])
该数据集为银行卡违约,付费后可以查看加密内容,获取下载链接,若链接失效,联系微信yeeyea
打赏2.0元
手机端:用系统浏览器访问本链接,打开支付宝完成打赏
订单号示例
1.微信中:截图保存支付宝绿码,支付宝扫码打赏,手动获取;
2.电脑端:使用手机支付宝直接扫绿码,完成打赏,自动获取;